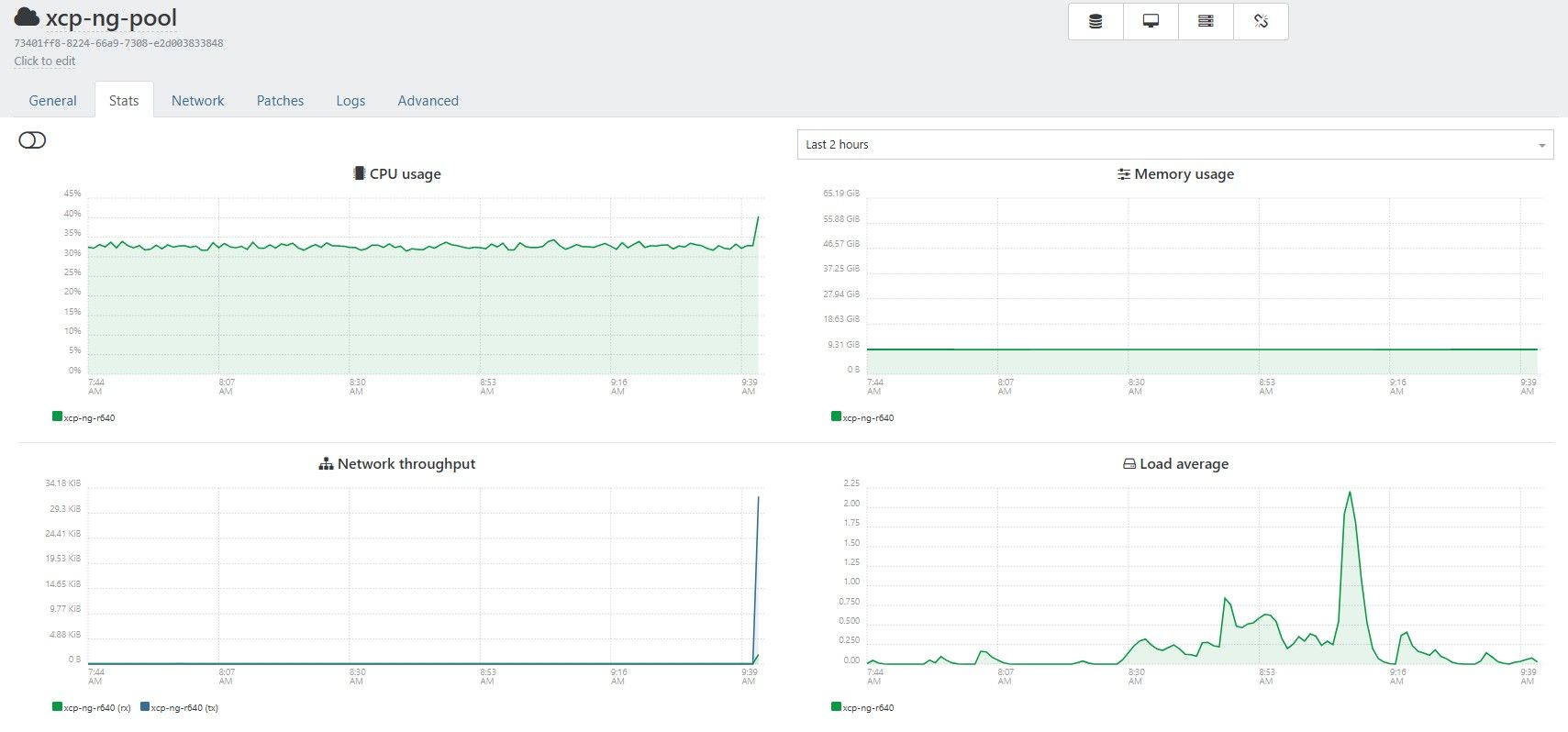
Hello @anthoineb,
We captured another occurrence on the same VM, os-ott-data-3-2
(172.30.52.193), on the same hypervisor and QCOW2 VDI as the incident
reported on 2026-07-25.
This occurrence is useful because xen_blkfront.max_ring_page_order=3 was
definitely active:
xenstore showed ring-page-order=3 with eight ring references;
the guest queue depth was 256;
255 write requests remained in flight;
all 256 blk-mq scheduler tags were busy;
wbt_lat_usec=0;
I/O PSI full was approximately 98%;
completed xvdb counters did not advance between samples.
The backend state was nevertheless the same as in the previous capture:
tapdisk was sleeping in scheduler_wait_for_events();
tap-ctl reported reqs_outstanding=0;
tap request counters were 0/0;
req_prod=0 and rsp_prod=0;
no tap, image, VBD, map or xenbus errors were reported.
One detail may be relevant: GDB still printed n_reqs=32 and
n_reqs_free=32, although the frontend had negotiated an order-3 ring and the
guest exposed 256 tags. Is this expected because n_reqs represents a separate
fixed tapdisk request pool, or could it indicate that tapdisk is not observing
the complete multi-page ring?
The controller captured GDB and the guest/hypervisor state before reboot. After
the ten-minute diagnostic window, the same signature was confirmed three more
times and the VM was rebooted. It rejoined the cluster successfully.
I have attached:
the complete GDB/tap-ctl capture;
the guest blk-mq, diskstats, PSI, D-state stack and kernel-journal snapshot;
the corresponding tapdisk/xenstore, daemon.log and SMlog excerpt;
a README and SHA-256 checksums.
The important new result appears to be that increasing
max_ring_page_order from 0 to 3 did not prevent the stall; the same mismatch
recurred with 255/256 frontend requests/tags occupied while the backend ring
and tapdisk remained empty.
20260730-005220-gdb-172.30.52.193.txt 20260730-pre-reboot-guest-172.30.52.193.txt 20260730-pre-reboot-hypervisor-172.30.50.191.txt README.txt SHA256SUMS.txt