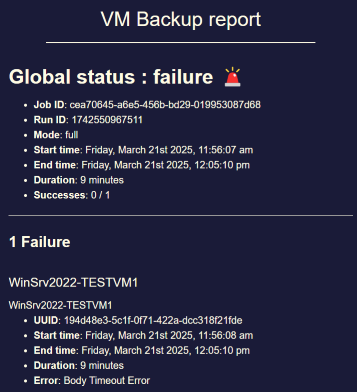
@ravenet Sure, gave that a whirl and no change, though I did notice some nvtop weirdness as it would show some load, but most of the wait time there was actually no load on the GPUs instead of the constant load matching the model being loaded. For some historical context ARI support was initially disabled in the bios when I started this thread. That was on the list of things I enabled when I started seeing some success with ollama (something in the changes since has broken ollama now too, but there was at least some forward progress after enabling). dmesg output overall looked the same, but I did see this output on the console (and in dmesg) that seemed interesting. Not 100% sure at this point if this was in the previous dmesg outputs or not, but may be worth sharing. EDIT: looks like this may actually be new... I looked back through the past dm dmesg outputs and I did not see this output.
[ 108.547683] amdgpu 0000:00:09.0: MES(0) failed to respond to msg=REMOVE_QUEUE
[ 108.547729] amdgpu 0000:00:09.0: failed to remove hardware queue from MES, doorbell=0x1202
[ 108.547746] amdgpu 0000:00:09.0: MES might be in unrecoverable state, issue a GPU reset
[ 108.547774] amdgpu 0000:00:09.0: Failed to evict queue 2
[ 108.547789] amdgpu 0000:00:09.0: Failed to evict process queues
[ 108.547803] amdgpu: Failed to quiesce KFD
[ 108.547870] amdgpu 0000:00:09.0: GPU reset begin!. Source: 3
[ 109.656850] amdgpu 0000:00:09.0: Failed to remove queue 0
[ 109.657324] amdgpu 0000:00:09.0: Dumping IP State
[ 109.756265] amdgpu 0000:00:09.0: Dumping IP State Completed
[ 112.047695] amdgpu 0000:00:09.0: MODE1 reset
[ 112.047797] amdgpu 0000:00:09.0: GPU mode1 reset
[ 112.054505] amdgpu 0000:00:09.0: GPU smu mode1 reset
[ 113.075393] amdgpu 0000:00:09.0: GPU reset succeeded, trying to resume
[ 113.090354] amdgpu 0000:00:09.0: [drm] PCIE GART of 512M enabled (table at 0x00000087D6B00000).
[ 113.092905] amdgpu 0000:00:09.0: [drm] AMDGPU device coredump file has been created
[ 113.092913] amdgpu 0000:00:09.0: [drm] Check your /sys/class/drm/card1/device/devcoredump/data
[ 113.092917] amdgpu 0000:00:09.0: VRAM is lost due to GPU reset!
[ 113.092921] amdgpu 0000:00:09.0: PSP is resuming...
[ 114.997591] amdgpu 0000:00:09.0: GECC is disabled, set amdgpu_ras_enable=1 to enable GECC in next boot cycle if needed
[ 115.091125] amdgpu 0000:00:09.0: RAP: optional rap ta ucode is not available
[ 115.091130] amdgpu 0000:00:09.0: SECUREDISPLAY: optional securedisplay ta ucode is not available
[ 115.091134] amdgpu 0000:00:09.0: SMU is resuming...
[ 115.091375] amdgpu 0000:00:09.0: smu driver if version = 0x0000002e, smu fw if version = 0x00000033, smu fw program = 0, smu fw version = 0x00684c00 (104.76.0)
[ 115.432371] amdgpu 0000:00:09.0: SMU is resumed successfully!
[ 115.445556] amdgpu 0000:00:09.0: program CP_MES_CNTL : 0x4000000
[ 115.445731] amdgpu 0000:00:09.0: program CP_MES_CNTL : 0xc000000
[ 115.750240] amdgpu 0000:00:09.0: [drm] DMUB hardware initialized: version=0x0A000800
As an update for other things I have tried, in order to eliminate hardware issues, or bios settings I tried installing proxmox and spinning up a VM there with both GPUs passed through and it worked just fine... With that feedback I did a fresh install of XCP-NG 8.3 and spun up a fresh VM using the same steps as I used on proxmox and still no dice. This leads me to believe the issue is somewhere in the XCP-NG passthrough stack with my specific hardware...