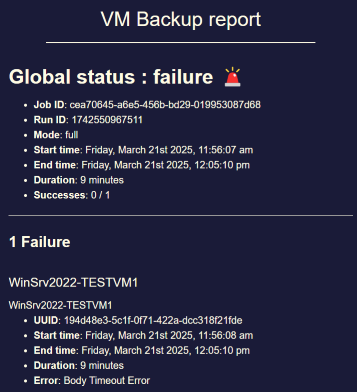
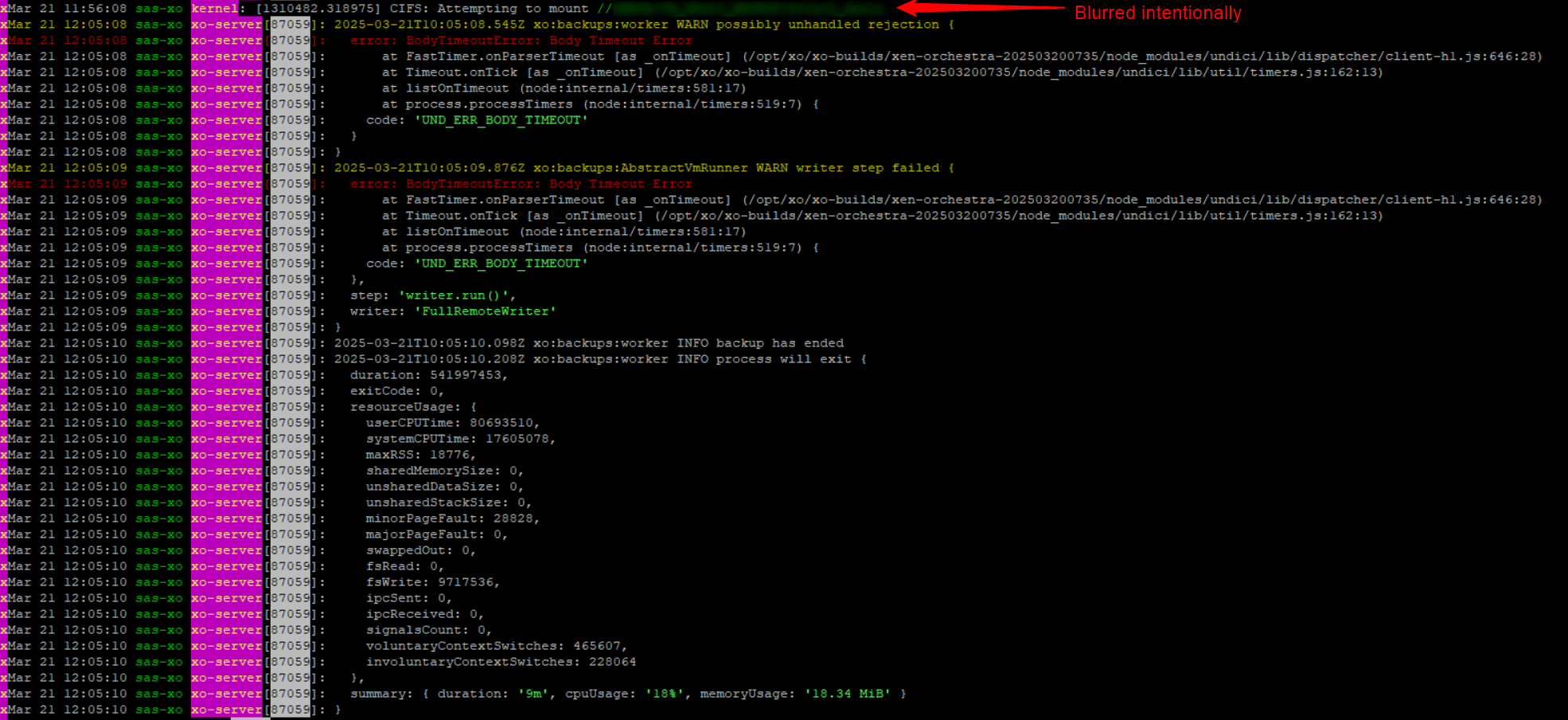
Potential bug with Windows VM backup: "Body Timeout Error"
-
@CodeMercenary alright, thanks for replying. I tried some more, but still getting the same error, on linux as well as windows vm's so im at lost here.
-
@nikade Hey Nikade,
Did you try to create a new job that will do a new chain ? Just for test.
-
@Pilow We tried that as well, same problem

Also tried with a VM on the same newtork, just another VLAN, and we're seeing the same thing. At first we figured it was because one of the xcp-ng's was on a remote site which is connected through an IPSEC VPN, but that wasn't the case.
-
Reviving this one because it never really got a clean ending. The fix for the Body Timeout Error on full backups went into xapi-project/xen-api#6786 and shipped with the March 2026 8.3 maintenance updates.
@nikade, back in March, you mentioned still hitting it on both Linux and Windows VMs even after updating. Is that still the case for you on current versions? And anyone else who landed here: are you still seeing it, or did the update sort it out?
Mostly trying to work out whether there's still something to chase or whether we can call this resolved. I'm not deep enough in the backup internals to say for sure, so your real-world results would tell us far more than anything I could guess. Thanks!
-
I need to update a few things and then I plan on trying to see if this was fixed for me. I think I only had 2 Windows machines that were a problem, and only on machines that had a larger disk and were basically empty. The counting zeros seemed to lead to a time out. Just haven't had the time to look at much of anything lately.
-
@poddingue My colleage managed to workaround the issue by re-installing the lab on other hardware, I think it is now Cisco UCS-servers. It was HP ProLiant-servers before.
Maybe it was an issue with some of the NIC or firmware, im not really sure, but it works now.
-
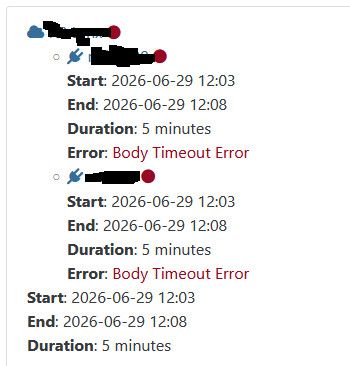
I get this error with each metadata backup run, but every time it fail on different pool. Only 1 failed pool at once.
-
@Tristis-Oris Hi,
Can you upload your complete logs from one of these jobs, please? You can DM me if you prefer")
-
@poddingue I have asked our engineers for feedback. We have left one big VM with 1TB empty disk - and full backups are going without errors for one week.
So it seems issue is resolved.
I have to mention that during this time we have migrated to XCP-NG 8.3. and are using one of the latest XO builds. -
That's excellent news, thanks a lot for the feedback!

-
commit 63f8d, (Ronivay script)
Got this error on my test ofTWINSTOR: next gen 2 nodes HCI
First I ran the job manually (metadata and config), OK
Then the scheduled job ran with this error on the metadata.
{ reportWhen: "failure" } id "1783045813184" jobId "e664efb6-9514-4e6b-8303-f236ad4dbfb9" jobName "twin-conf" message "backup" scheduleId "d343fdd7-9dde-4695-adec-ba2eb43f23d2" start 1783045813184 status "failure" tasks [ {…}, {…} ] end 1783046114017 result { message: "backup task failed with undefined error", name: "Error", stack: "Error: backup task failed with undefined error\n at forwardResult (file:///opt/xo/xo-builds/xen-orchestra-202607020951/pa….runJobSequence (file:///opt/xo/xo-builds/xen-orchestra-202607020951/packages/xo-server/src/xo-mixins/jobs/index.mjs:339:7)" }Config seems to be OK
-
Hi,
Would be nice to have the entire log
Could it be possible that the master or the pool was not reachable at the time of the metadata backup?
-
@olivierlambert
Removed the uefi_certificates{ "data": { "reportWhen": "failure" }, "id": "1783045813184", "jobId": "e664efb6-9514-4e6b-8303-f236ad4dbfb9", "jobName": "twin-conf", "message": "backup", "scheduleId": "d343fdd7-9dde-4695-adec-ba2eb43f23d2", "start": 1783045813184, "status": "failure", "tasks": [ { "id": "0mr4bfumi-dzqwb7948p", "start": 1783045813194, "status": "success", "tasks": [ { "id": "0mr4bfumi-9kdhhby2p5", "start": 1783045813194, "status": "success", "end": 1783045813258, "message": "Starting XO metadata backup for the remote (da08058c-c031-499d-b423-52b1e76380ed). (e664efb6-9514-4e6b-8303-f236ad4dbfb9)", "data": { "id": "da08058c-c031-499d-b423-52b1e76380ed", "type": "remote" } } ], "end": 1783045813259, "message": "Starting XO metadata backup. (e664efb6-9514-4e6b-8303-f236ad4dbfb9)", "data": { "type": "xo" } }, { "id": "0mr4bfuml-bqp15noo59i", "start": 1783045813197, "status": "failure", "tasks": [ { "id": "0mr4bfun2-d0l56rvwtg", "start": 1783045813214, "status": "failure", "end": 1783046113969, "result": { "name": "BodyTimeoutError", "code": "UND_ERR_BODY_TIMEOUT", "message": "Body Timeout Error", "stack": "BodyTimeoutError: Body Timeout Error\n at FastTimer.onParserTimeout [as _onTimeout] (/opt/xo/xo-builds/xen-orchestra-202607020951/node_modules/undici/lib/dispatcher/client-h1.js:688:28)\n at Timeout.onTick [as _onTimeout] (/opt/xo/xo-builds/xen-orchestra-202607020951/node_modules/undici/lib/util/timers.js:162:13)\n at listOnTimeout (node:internal/timers:605:17)\n at processTimers (node:internal/timers:541:7)" }, "message": "Starting metadata backup for the pool (7e461b17-b34e-5e10-277b-84677bb207bf) for the remote (da08058c-c031-499d-b423-52b1e76380ed). (e664efb6-9514-4e6b-8303-f236ad4dbfb9)", "data": { "id": "da08058c-c031-499d-b423-52b1e76380ed", "type": "remote", "progress": 0 } } ], "end": 1783046113971, "message": "Starting metadata backup for the pool (7e461b17-b34e-5e10-277b-84677bb207bf). (e664efb6-9514-4e6b-8303-f236ad4dbfb9)", "data": { "id": "7e461b17-b34e-5e10-277b-84677bb207bf", "pool": { "uuid": "7e461b17-b34e-5e10-277b-84677bb207bf", "name_label": "Middle-earth", "name_description": "", "master": "OpaqueRef:5ceac8f1-744c-13b0-0652-75fdff79f6c9", "default_SR": "OpaqueRef:NULL", "suspend_image_SR": "OpaqueRef:NULL", "crash_dump_SR": "OpaqueRef:NULL", "other_config": { "xo:clientInfo:zffyon3svem": "{\"lastConnected\":1783034682565,\"networkInterfaces\":{\"enX0\":[{\"address\":\"192.168.11.104\",\"netmask\":\"255.255.255.0\",\"family\":\"IPv4\",\"mac\":\"a6:7c:87:67:5e:41\",\"internal\":false,\"cidr\":\"192.168.11.104/24\"},{\"address\":\"fe80::a47c:87ff:fe67:5e41\",\"netmask\":\"ffff:ffff:ffff:ffff::\",\"family\":\"IPv6\",\"mac\":\"a6:7c:87:67:5e:41\",\"internal\":false,\"cidr\":\"fe80::a47c:87ff:fe67:5e41/64\",\"scopeid\":2}]}}", "xo:clientInfo:c725c94e-296d-61d8-23a0-f07c63520f65": "{\"lastConnected\":1783013072625,\"networkInterfaces\":{\"enX0\":[{\"address\":\"192.168.11.101\",\"netmask\":\"255.255.255.0\",\"family\":\"IPv4\",\"mac\":\"e2:7f:90:57:75:a6\",\"internal\":false,\"cidr\":\"192.168.11.101/24\"},{\"address\":\"fe80::e07f:90ff:fe57:75a6\",\"netmask\":\"ffff:ffff:ffff:ffff::\",\"family\":\"IPv6\",\"mac\":\"e2:7f:90:57:75:a6\",\"internal\":false,\"cidr\":\"fe80::e07f:90ff:fe57:75a6/64\",\"scopeid\":2}]}}", "xo:clientInfo:9kul7pgojmd": "{\"lastConnected\":1783002005305,\"networkInterfaces\":{\"enX0\":[{\"address\":\"192.168.11.104\",\"netmask\":\"255.255.255.0\",\"family\":\"IPv4\",\"mac\":\"a6:7c:87:67:5e:41\",\"internal\":false,\"cidr\":\"192.168.11.104/24\"},{\"address\":\"fe80::a47c:87ff:fe67:5e41\",\"netmask\":\"ffff:ffff:ffff:ffff::\",\"family\":\"IPv6\",\"mac\":\"a6:7c:87:67:5e:41\",\"internal\":false,\"cidr\":\"fe80::a47c:87ff:fe67:5e41/64\",\"scopeid\":2}]}}", "xo:clientInfo:0rwhmux9ihqm": "{\"lastConnected\":1782989396232,\"networkInterfaces\":{\"enX0\":[{\"address\":\"192.168.11.104\",\"netmask\":\"255.255.255.0\",\"family\":\"IPv4\",\"mac\":\"a6:7c:87:67:5e:41\",\"internal\":false,\"cidr\":\"192.168.11.104/24\"},{\"address\":\"fe80::a47c:87ff:fe67:5e41\",\"netmask\":\"ffff:ffff:ffff:ffff::\",\"family\":\"IPv6\",\"mac\":\"a6:7c:87:67:5e:41\",\"internal\":false,\"cidr\":\"fe80::a47c:87ff:fe67:5e41/64\",\"scopeid\":2}]}}", "xo:clientInfo:4gtha9oducv": "{\"lastConnected\":1782983029680,\"networkInterfaces\":{\"enX0\":[{\"address\":\"192.168.11.104\",\"netmask\":\"255.255.255.0\",\"family\":\"IPv4\",\"mac\":\"a6:7c:87:67:5e:41\",\"internal\":false,\"cidr\":\"192.168.11.104/24\"},{\"address\":\"fe80::a47c:87ff:fe67:5e41\",\"netmask\":\"ffff:ffff:ffff:ffff::\",\"family\":\"IPv6\",\"mac\":\"a6:7c:87:67:5e:41\",\"internal\":false,\"cidr\":\"fe80::a47c:87ff:fe67:5e41/64\",\"scopeid\":2}]}}", "auto_poweron": "true", "xo:clientInfo:7f8ngv9i6st": "{\"lastConnected\":1782946813358,\"networkInterfaces\":{\"enX0\":[{\"address\":\"192.168.11.102\",\"netmask\":\"255.255.255.0\",\"family\":\"IPv4\",\"mac\":\"ae:f5:9b:89:01:07\",\"internal\":false,\"cidr\":\"192.168.11.102/24\"},{\"address\":\"fe80::acf5:9bff:fe89:107\",\"netmask\":\"ffff:ffff:ffff:ffff::\",\"family\":\"IPv6\",\"mac\":\"ae:f5:9b:89:01:07\",\"internal\":false,\"cidr\":\"fe80::acf5:9bff:fe89:107/64\",\"scopeid\":2}]}}", "xo:clientInfo:1hfj1o99bag": "{\"lastConnected\":1782945346185,\"networkInterfaces\":{\"enX0\":[{\"address\":\"192.168.11.102\",\"netmask\":\"255.255.255.0\",\"family\":\"IPv4\",\"mac\":\"ae:f5:9b:89:01:07\",\"internal\":false,\"cidr\":\"192.168.11.102/24\"},{\"address\":\"fe80::acf5:9bff:fe89:107\",\"netmask\":\"ffff:ffff:ffff:ffff::\",\"family\":\"IPv6\",\"mac\":\"ae:f5:9b:89:01:07\",\"internal\":false,\"cidr\":\"fe80::acf5:9bff:fe89:107/64\",\"scopeid\":2}]}}", "memory-ratio-hvm": "0.25", "memory-ratio-pv": "0.25" }, "ha_enabled": true, "ha_configuration": {}, "ha_statefiles": [ "OpaqueRef:1088109f-4634-2d30-6d7d-4b120dd09690" ], "ha_host_failures_to_tolerate": 1, "ha_plan_exists_for": 1, "ha_allow_overcommit": false, "ha_overcommitted": false, "blobs": {}, "tags": [], "gui_config": {}, "health_check_config": {}, "wlb_url": "", "wlb_username": "", "wlb_enabled": false, "wlb_verify_cert": true, "redo_log_enabled": false, "redo_log_vdi": "OpaqueRef:NULL", "vswitch_controller": "", "restrictions": { "restrict_vswitch_controller": "false", "restrict_lab": "false", "restrict_stage": "false", "restrict_storagelink": "false", "restrict_storagelink_site_recovery": "false", "restrict_web_selfservice": "false", "restrict_web_selfservice_manager": "false", "restrict_hotfix_apply": "false", "restrict_export_resource_data": "false", "restrict_read_caching": "false", "restrict_cifs": "false", "restrict_health_check": "false", "restrict_xcm": "false", "restrict_vm_memory_introspection": "false", "restrict_batch_hotfix_apply": "false", "restrict_management_on_vlan": "false", "restrict_ws_proxy": "false", "restrict_cloud_management": "false", "restrict_nrpe": "false", "restrict_vlan": "false", "restrict_qos": "false", "restrict_pool_attached_storage": "false", "restrict_netapp": "false", "restrict_equalogic": "false", "restrict_pooling": "false", "enable_xha": "true", "restrict_marathon": "false", "restrict_email_alerting": "false", "restrict_historical_performance": "false", "restrict_wlb": "false", "restrict_rbac": "false", "restrict_dmc": "false", "restrict_checkpoint": "false", "restrict_cpu_masking": "false", "restrict_connection": "false", "platform_filter": "false", "regular_nag_dialog": "false", "restrict_vmpr": "false", "restrict_vmss": "false", "restrict_intellicache": "false", "restrict_gpu": "false", "restrict_dr": "false", "restrict_vif_locking": "false", "restrict_storage_xen_motion": "false", "restrict_vgpu": "false", "restrict_integrated_gpu_passthrough": "false", "restrict_vss": "false", "restrict_guest_agent_auto_update": "false", "restrict_pci_device_for_auto_update": "false", "restrict_xen_motion": "false", "restrict_guest_ip_setting": "false", "restrict_ad": "false", "restrict_nested_virt": "false", "restrict_live_patching": "false", "restrict_set_vcpus_number_live": "false", "restrict_pvs_proxy": "false", "restrict_igmp_snooping": "false", "restrict_rpu": "false", "restrict_pool_size": "false", "restrict_cbt": "false", "restrict_usb_passthrough": "false", "restrict_network_sriov": "false", "restrict_corosync": "true", "restrict_cluster_address": "false", "restrict_zstd_export": "false", "restrict_pool_secret_rotation": "false", "restrict_certificate_verification": "false", "restrict_updates": "false", "restrict_internal_repo_access": "false", "restrict_vtpm": "false", "restrict_vm_groups": "false", "restrict_vm_start": "false", "restrict_vm_appliance_start": "false" }, "metadata_VDIs": [], "ha_cluster_stack": "xhad", "allowed_operations": [ "ha_disable", "designate_new_master", "configure_repositories", "sync_updates", "sync_bundle", "apply_updates", "cert_refresh", "exchange_certificates_on_join", "exchange_ca_certificates_on_join", "copy_primary_host_certs", "eject", "get_updates" ], "current_operations": {}, "guest_agent_config": {}, "cpu_info": { "features_hvm_host": "1fcbfbff-f7fa3203-2c100800-00000021-00000001-000007ab-00000000-00000000-00101000-bc000400-00000000-00000000-00000000-00000000-00000000-00000000-0c000004-40000000-00000000-00000000-00000000-00000000-00000000", "features_pv_host": "1fc9cbf5-f6d83203-28100800-00000021-00000001-00000329-00000000-00000000-00001000-ac000400-00000000-00000000-00000000-00000000-00000000-00000000-0c000004-40000000-00000000-00000000-00000000-00000000-00000000", "socket_count": "2", "cpu_count": "16", "vendor": "GenuineIntel" }, "policy_no_vendor_device": false, "live_patching_disabled": false, "igmp_snooping_enabled": false, "uefi_certificates": # removed # "custom_uefi_certificates": "", "is_psr_pending": false, "tls_verification_enabled": true, "repositories": [], "client_certificate_auth_enabled": false, "client_certificate_auth_name": "", "repository_proxy_url": "", "repository_proxy_username": "", "repository_proxy_password": "OpaqueRef:NULL", "migration_compression": false, "coordinator_bias": true, "local_auth_max_threads": 8, "ext_auth_max_threads": 1, "ext_auth_cache_enabled": false, "ext_auth_cache_size": 50, "ext_auth_cache_expiry": 300, "telemetry_uuid": "OpaqueRef:b19f5323-f179-a7b7-3e45-0cbd78992b0e", "telemetry_frequency": "weekly", "telemetry_next_collection": "20260702T23:44:39Z", "last_update_sync": "19700101T00:00:00Z", "update_sync_frequency": "weekly", "update_sync_day": 0, "update_sync_enabled": false, "recommendations": { "max-vm-anti-affinity-groups": "5" }, "license_server": {}, "ha_reboot_vm_on_internal_shutdown": true, "limit_console_sessions": false, "vm_console_idle_timeout": 0 }, "poolMaster": { "uuid": "aae1f2ab-1f2f-4a38-af90-97d850a2caaf", "name_label": "saruman", "name_description": "Default install", "memory_overhead": 463126528, "allowed_operations": [ "vm_migrate", "provision", "vm_resume", "enable", "evacuate", "vm_start" ], "current_operations": {}, "API_version_major": 2, "API_version_minor": 21, "API_version_vendor": "XenSource", "API_version_vendor_implementation": {}, "enabled": true, "software_version": { "product_version": "8.3.0", "product_version_text": "8.3", "product_version_text_short": "8.3", "platform_name": "XCP", "platform_version": "3.4.0", "product_brand": "XCP-ng", "xapi": "26.1", "build_number": "8.3.0", "git_id": "11", "hostname": "localhost", "date": "20260618T12:39:30Z", "dbv": "2026.0202", "xapi_build": "26.1.11", "xen": "4.17.6-9", "linux": "4.19.0+1", "xencenter_min": "2.21", "xencenter_max": "2.21", "network_backend": "openvswitch", "db_schema": "5.795" }, "other_config": { "agent_start_time": "1783013042.", "boot_time": "1783012910.", "multipathhandle": "dmp", "multipathing": "true", "last_blob_sync_time": "1782941656.94", "iscsi_iqn": "iqn.2026-07.com.example:9a839973" }, "capabilities": [ "xen-3.0-x86_64", "hvm-3.0-x86_32", "hvm-3.0-x86_32p", "hvm-3.0-x86_64", "" ], "cpu_configuration": {}, "sched_policy": "credit", "supported_bootloaders": [ "pygrub", "eliloader" ], "resident_VMs": [ "OpaqueRef:b4cb1c1e-8c91-178b-74be-7528a4c2dcc0", "OpaqueRef:4a3ee368-0fb7-dba6-eb3e-6cf4456f9e84" ], "logging": {}, "PIFs": [ "OpaqueRef:b9de3d0c-a8c6-6b96-9248-4b8ee7de8e86" ], "suspend_image_sr": "OpaqueRef:NULL", "crash_dump_sr": "OpaqueRef:NULL", "crashdumps": [], "patches": [], "updates": [], "PBDs": [ "OpaqueRef:d435ddeb-af36-ae51-67b5-2f711ba4c2a9", "OpaqueRef:c5b01445-3d66-d589-124f-d8edaf3389e8", "OpaqueRef:735a54e2-505d-afaa-3522-b99621ffdb44", "OpaqueRef:5c175bce-c41d-d97d-d108-fcbd16a601d4", "OpaqueRef:528cbc67-88d9-465c-0e99-2a11602a4ff9" ], "host_CPUs": [ "OpaqueRef:543628ec-dab6-a811-c4ac-94a878c4fd0b", "OpaqueRef:ed0d5baf-537f-03a4-ed99-9d4c21321a5b", "OpaqueRef:0ac07111-529a-6fc9-16e2-bd444fbca1e1", "OpaqueRef:9188a89f-112b-8121-227d-fb88322d21d0", "OpaqueRef:669b605f-9c0f-1577-7d2a-cb64dc936f05", "OpaqueRef:826404a3-6afd-0458-aaf6-f7220a376c0d", "OpaqueRef:afd77111-fbb5-0d75-9be8-0d3ecd5cfbf6", "OpaqueRef:81eff8c4-8dd4-0b54-d8c8-b247d6c0acac" ], "cpu_info": { "cpu_count": "8", "socket_count": "1", "threads_per_core": "2", "nr_nodes": "1", "vendor": "GenuineIntel", "speed": "1800.005", "modelname": "Intel(R) Core(TM) i5-8250U CPU @ 1.60GHz", "family": "6", "model": "142", "stepping": "10", "flags": "fpu de tsc msr pae mce cx8 apic sep mca cmov pat clflush acpi mmx fxsr sse sse2 ss ht syscall nx rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid pni pclmulqdq monitor est ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch cpuid_fault ssbd ibrs ibpb stibp fsgsbase bmi1 avx2 bmi2 erms rdseed adx clflushopt xsaveopt xsavec xgetbv1 arch_capabilities", "features_pv": "1fc9cbf5-f6f83203-2991cbf5-00000123-00000007-008c0329-00000000-00000100-00001000-ac000400-00000000-00000000-00000000-00000000-00000000-00000000-1c020004-40000000-00000000-00000000-00000000-00000000-00000000", "features_hvm": "1fcbfbff-f7fa3223-2d93fbff-00000523-0000000f-009c47ab-00000000-00000100-00101000-bc000400-00000000-00000000-00000000-00000000-00000000-00000000-1c020004-40000000-00000000-00000000-00000000-00000000-00000000", "features_hvm_host": "1fcbfbff-f7fa3203-2c100800-00000121-0000000f-009c07ab-00000000-00000000-00101000-bc000400-00000000-00000000-00000000-00000000-00000000-00000000-0c000004-40000000-00000000-00000000-00000000-00000000-00000000", "features_pv_host": "1fc9cbf5-f6d83203-28100800-00000121-00000007-008c0329-00000000-00000000-00001000-ac000400-00000000-00000000-00000000-00000000-00000000-00000000-0c000004-40000000-00000000-00000000-00000000-00000000-00000000" }, "hostname": "saruman", "address": "192.168.11.23", "metrics": "OpaqueRef:5ba864f1-c495-0787-d239-947f0d6f99d4", "license_params": { "restrict_vswitch_controller": "false", "restrict_lab": "false", "restrict_stage": "false", "restrict_storagelink": "false", "restrict_storagelink_site_recovery": "false", "restrict_web_selfservice": "false", "restrict_web_selfservice_manager": "false", "restrict_hotfix_apply": "false", "restrict_export_resource_data": "false", "restrict_read_caching": "false", "restrict_cifs": "false", "restrict_health_check": "false", "restrict_xcm": "false", "restrict_vm_memory_introspection": "false", "restrict_batch_hotfix_apply": "false", "restrict_management_on_vlan": "false", "restrict_ws_proxy": "false", "restrict_cloud_management": "false", "restrict_nrpe": "false", "restrict_vlan": "false", "restrict_qos": "false", "restrict_pool_attached_storage": "false", "restrict_netapp": "false", "restrict_equalogic": "false", "restrict_pooling": "false", "enable_xha": "true", "restrict_marathon": "false", "restrict_email_alerting": "false", "restrict_historical_performance": "false", "restrict_wlb": "false", "restrict_rbac": "false", "restrict_dmc": "false", "restrict_checkpoint": "false", "restrict_cpu_masking": "false", "restrict_connection": "false", "platform_filter": "false", "regular_nag_dialog": "false", "restrict_vmpr": "false", "restrict_vmss": "false", "restrict_intellicache": "false", "restrict_gpu": "false", "restrict_dr": "false", "restrict_vif_locking": "false", "restrict_storage_xen_motion": "false", "restrict_vgpu": "false", "restrict_integrated_gpu_passthrough": "false", "restrict_vss": "false", "restrict_guest_agent_auto_update": "false", "restrict_pci_device_for_auto_update": "false", "restrict_xen_motion": "false", "restrict_guest_ip_setting": "false", "restrict_ad": "false", "restrict_nested_virt": "false", "restrict_live_patching": "false", "restrict_set_vcpus_number_live": "false", "restrict_pvs_proxy": "false", "restrict_igmp_snooping": "false", "restrict_rpu": "false", "restrict_pool_size": "false", "restrict_cbt": "false", "restrict_usb_passthrough": "false", "restrict_network_sriov": "false", "restrict_corosync": "true", "restrict_cluster_address": "false", "restrict_zstd_export": "false", "restrict_pool_secret_rotation": "false", "restrict_certificate_verification": "false", "restrict_updates": "false", "restrict_internal_repo_access": "false", "restrict_vtpm": "false", "restrict_vm_groups": "false", "restrict_vm_start": "false", "restrict_vm_appliance_start": "false" }, "ha_statefiles": [ "OpaqueRef:1088109f-4634-2d30-6d7d-4b120dd09690" ], "ha_network_peers": [ "8c67881d-e100-4a02-9e8d-98aac410e6b0", "aae1f2ab-1f2f-4a38-af90-97d850a2caaf" ], "blobs": {}, "tags": [], "external_auth_type": "", "external_auth_service_name": "", "external_auth_configuration": {}, "edition": "xcp-ng", "license_server": { "address": "localhost", "port": "27000" }, "bios_strings": { "bios-vendor": "HP", "bios-version": "Q83 Ver. 01.31.00", "system-manufacturer": "HP", "system-product-name": "HP ProBook 640 G4", "system-version": "SBKPF", "system-serial-number": "5CG83432QF", "baseboard-manufacturer": "HP", "baseboard-product-name": "83D2", "baseboard-version": "KBC Version 05.4E.00", "baseboard-serial-number": "PGWKH00WBB71HJ", "oem-1": "Xen", "oem-2": "MS_VM_CERT/SHA1/bdbeb6e0a816d43fa6d3fe8aaef04c2bad9d3e3d", "oem-3": "FBYTE#3X476J6S6b7B7H7M7Q7W7m7saBaEapaqauawbUbhcAdQdUdpdqfAgdhk.Dt;", "oem-4": "BUILDID#17WWC6BT601#SAK8#DAK8;", "oem-5": "EDK2_1", "oem-6": "Buff=2", "oem-7": "HRDWFEATS=VTX:1;VTD:1;SGX:2;NONHPBATDET:1", "hp-rombios": "" }, "power_on_mode": "", "power_on_config": {}, "local_cache_sr": "OpaqueRef:NULL", "chipset_info": { "iommu": "true" }, "PCIs": [ "OpaqueRef:d69ea10d-4a28-305b-bc77-c5b325b5efca", "OpaqueRef:d3b82ebd-72be-7b4d-aeb0-45286ba30820", "OpaqueRef:963b2435-0607-a303-c312-f841673e644d", "OpaqueRef:91af9331-a1a4-3025-073b-dd347fb9b0cf", "OpaqueRef:6326bf67-6291-e5b5-a028-990f642bb113", "OpaqueRef:3d4982c9-e712-610a-01d8-570f8cabd276", "OpaqueRef:1a62277c-19dd-df1b-d9e0-5d9991ee031c", "OpaqueRef:04ce1fdb-f128-5e1d-6567-dc35ab79204a" ], "PGPUs": [ "OpaqueRef:8f35fe69-4c6d-c0c1-3958-26a98932d691" ], "PUSBs": [], "ssl_legacy": false, "guest_VCPUs_params": {}, "display": "enabled", "virtual_hardware_platform_versions": [ 0, 1, 2 ], "control_domain": "OpaqueRef:4a3ee368-0fb7-dba6-eb3e-6cf4456f9e84", "updates_requiring_reboot": [], "features": [], "iscsi_iqn": "iqn.2026-07.com.example:9a839973", "multipathing": true, "uefi_certificates": # removed # "certificates": [ "OpaqueRef:f3d58304-b037-5739-b57f-3d301b18a7ff", "OpaqueRef:0dc9c6bd-0fb7-de23-70d2-4bc2bef46c17" ], "editions": [ "xcp-ng" ], "pending_guidances": [], "tls_verification_enabled": true, "last_software_update": "19700101T00:00:00Z", "https_only": false, "latest_synced_updates_applied": "unknown", "numa_affinity_policy": "default_policy", "pending_guidances_recommended": [], "pending_guidances_full": [], "last_update_hash": "", "ssh_enabled": true, "ssh_enabled_timeout": 0, "ssh_expiry": "19700101T00:00:00Z", "console_idle_timeout": 0, "ssh_auto_mode": false, "max_cstate": "", "secure_boot": false, "ntp_mode": "DHCP", "ntp_custom_servers": [], "timezone": "Europe/Stockholm" }, "type": "pool" } } ], "end": 1783046114017, "result": { "message": "backup task failed with undefined error", "name": "Error", "stack": "Error: backup task failed with undefined error\n at forwardResult (file:///opt/xo/xo-builds/xen-orchestra-202607020951/packages/xo-server/src/_handleBackupLog.mjs:37:25)\n at handleBackupLog (file:///opt/xo/xo-builds/xen-orchestra-202607020951/packages/xo-server/src/_handleBackupLog.mjs:68:12)\n at onTaskUpdate (file:///opt/xo/xo-builds/xen-orchestra-202607020951/packages/xo-server/src/xo-mixins/metadata-backups.mjs:133:13)\n at onTaskUpdate (file:///opt/xo/xo-builds/xen-orchestra-202607020951/@xen-orchestra/mixins/Tasks.mjs:205:23)\n at Task.onProgress [as _onProgress] (/opt/xo/xo-builds/xen-orchestra-202607020951/@vates/task/combineEvents.js:61:5)\n at Task.#emit (/opt/xo/xo-builds/xen-orchestra-202607020951/@vates/task/index.js:157:10)\n at Task.#end (/opt/xo/xo-builds/xen-orchestra-202607020951/@vates/task/index.js:168:15)\n at Task.run (/opt/xo/xo-builds/xen-orchestra-202607020951/@vates/task/index.js:190:16)\n at Jobs.runJob (file:///opt/xo/xo-builds/xen-orchestra-202607020951/packages/xo-server/src/xo-mixins/jobs/index.mjs:297:7)\n at Jobs.runJobSequence (file:///opt/xo/xo-builds/xen-orchestra-202607020951/packages/xo-server/src/xo-mixins/jobs/index.mjs:339:7)" } }Could it be possible that the master or the pool was not reachable at the time of the metadata backup?
Don't think so.
The config ran OK at 04:30 but metadata did not, see above
And the backup job 5 min later ran OK -
Thanks for the logs @ph7, that helps narrow it down.
Some context on what this error actually means: XO's XAPI client kills the connection if it receives nothing from the pool master for 5 minutes during the transfer. So the
BodyTimeoutErroron a metadata backup means the/pool/xmldbdumpresponse from your master went silent. Either xapi stalled while producing the dump, or the connection died silently somewhere in between (a NAT/firewall/VPN dropping the connection state would look exactly like this). Note that your XO config backup succeeding right before doesn't rule out a network issue: the config backup only talks to the remote, it never touches the pool master.To figure out which side is failing, could you check a few things?
- On your backup remote, look at the file left behind by the failed run:
xo-pool-metadata-backups/<scheduleId>/<poolUuid>/<date>/data. What size is it, compared to the same file from a successful run? If it's empty or tiny, the master stalled. If it looks complete, the data actually arrived and only the end-of-connection signal got lost, which would point at the network path. - On the pool master, grab
/var/log/xensource.logaround the failure time. There should be a task named "Export pool metadata" and the xmldbdump HTTP handler. We'd like to know if it completed on the xapi side. - Is there anything between your XO and the pool master, like NAT, a firewall or a VPN?
- Does it fail every run, or intermittently?
@Tristis-Oris the same questions apply to your setup. The fact that it hits different pools one after the other makes me suspect something shared in the network path.
- On your backup remote, look at the file left behind by the failed run:
-
@olivierlambert for now it solved after toolstack restart everywhere.
-
Is there anything between your XO and the pool master, like NAT, a firewall or a VPN?
No, XO is running on master (twinstor)
Both hosts connected to the same switch
the remote is 2 swithes away
same switches as my "production" poolDoes it fail every run, or intermittently?
Only run scheduled once, manually once.
I will increase the schedule to more than once a dayMore answers to come later.
-
On the pool master, grab /var/log/xensource.log around the failure time
Jul 3 04:30:01 saruman xapi: [ info||29324 /var/lib/xcp/xapi|session.login_with_password D:908fdbb626db|xapi_session] Session.create trackid=41a9bd376a47b30a10d3095904460bd3 pool=false uname=__dom0__vmss or$ Jul 3 04:30:01 saruman xapi: [debug||29325 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:pool.get_all D:ea7b81b697f8 created by task D:908fdbb626db Jul 3 04:30:01 saruman xapi: [ info||29324 /var/lib/xcp/xapi|session.logout D:5487db4e0230|xapi_session] Session.destroy trackid=41a9bd376a47b30a10d3095904460bd3 Jul 3 04:30:11 saruman xapi: [debug||253 scanning_thread|SR scanner D:326d57d887b1|xapi_sr] Automatically scanning SRs = [ OpaqueRef:16725e54-2f51-9bcc-0a1b-31847b9d2bfb ] Jul 3 04:30:11 saruman xapi: [debug||29327 ||dummytaskhelper] task scan one D:087ea22e0ee5 created by task D:326d57d887b1 Jul 3 04:30:11 saruman xapi: [debug||29328 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:session.slave_login D:8c110ea47053 created by task D:087ea22e0ee5 Jul 3 04:30:11 saruman xapi: [ info||29328 /var/lib/xcp/xapi|session.slave_login D:3e88d5649d68|xapi_session] Session.create trackid=5c51ddc5b8505a581894127d43e2343d pool=true uname= originator=xapi is_loca$ Jul 3 04:30:11 saruman xapi: [debug||29329 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:pool.get_all D:7b13505bd888 created by task D:3e88d5649d68 Jul 3 04:30:11 saruman xapi: [debug||29330 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:SR.scan D:d1b242a39442 created by task D:087ea22e0ee5 Jul 3 04:30:11 saruman xapi: [ info||29330 /var/lib/xcp/xapi|dispatch:SR.scan D:d1b242a39442|taskhelper] task SR.scan R:03361ab5f886 (uuid:15b82cce-bf75-992b-da5d-6f04d4e3cfb9) created (trackid=5c51ddc5b850$ Jul 3 04:30:11 saruman xapi: [debug||29330 /var/lib/xcp/xapi|SR.scan R:03361ab5f886|message_forwarding] SR.scan: SR = 'fd8042bf-61a9-e2cb-09e8-b6ea67086b15 (T1_ISO_test)' Jul 3 04:30:11 saruman xapi: [debug||29330 /var/lib/xcp/xapi|SR.scan R:03361ab5f886|message_forwarding] Marking SR for SR.scan (task=OpaqueRef:03361ab5-f886-e53b-8e84-1eb561e1287c) Jul 3 04:30:11 saruman xapi: [ info||29330 /var/lib/xcp/xapi|OpaqueRef:03361ab5-f886-e53b-8e84-1eb561e1287c|mux] SR.scan2 dbg:OpaqueRef:03361ab5-f886-e53b-8e84-1eb561e1287c sr:fd8042bf-61a9-e2cb-09e8-b6ea67$ Jul 3 04:30:11 saruman xapi: [ info||29331 |OpaqueRef:03361ab5-f886-e53b-8e84-1eb561e1287c|Storage_smapiv1_wrapper] SR.scan2 dbg:OpaqueRef:03361ab5-f886-e53b-8e84-1eb561e1287c sr:fd8042bf-61a9-e2cb-09e8-b6e$ Jul 3 04:30:11 saruman xapi: [debug||29331 |OpaqueRef:03361ab5-f886-e53b-8e84-1eb561e1287c|dummytaskhelper] task SR.scan D:504e4e1bee7f created by task R:03361ab5f886 Jul 3 04:30:11 saruman xapi: [debug||29331 |SR.scan D:504e4e1bee7f|sm] SM iso sr_scan sr=OpaqueRef:16725e54-2f51-9bcc-0a1b-31847b9d2bfb Jul 3 04:30:11 saruman xapi: [ info||29331 |sm_exec D:f548aa962a5a|xapi_session] Session.create trackid=044d562d253caff4cbd0d76f8bb65cd9 pool=false uname= originator=xapi is_local_superuser=true auth_user_s$ Jul 3 04:30:11 saruman xapi: [debug||29332 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:pool.get_all D:b8c1baa8f334 created by task D:f548aa962a5a Jul 3 04:30:11 saruman xapi: [ info||10797 HTTPS 192.168.11.104->:::80|task.create D:a45084e5a903|taskhelper] task [XO] Export pool metadata R:b7395ffc7ea1 (uuid:f9bb687f-5913-c319-dbd2-18dcb0cef5f2) create$ Jul 3 04:30:11 saruman xapi: [debug||10797 :::80|handler:http/get_pool_xml_db_sync D:301dcbf87ec2|pool_db_sync] received request to write out db as xml Jul 3 04:30:11 saruman xapi: [ info||10797 :::80|handler:http/get_pool_xml_db_sync D:301dcbf87ec2|taskhelper] task [XO] Export pool metadata R:b7395ffc7ea1 forwarded (trackid=8c3d92d008ac49afc3050fb20e404bb$ Jul 3 04:30:11 saruman xapi: [debug||10797 HTTPS 192.168.11.104->:::80|[XO] Export pool metadata R:b7395ffc7ea1|pool_db_sync] sending headers Jul 3 04:30:11 saruman xapi: [debug||10797 HTTPS 192.168.11.104->:::80|[XO] Export pool metadata R:b7395ffc7ea1|pool_db_sync] writing database xml Jul 3 04:30:11 saruman xapi: [debug||10797 HTTPS 192.168.11.104->:::80|[XO] Export pool metadata R:b7395ffc7ea1|pool_db_sync] finished writing database xml Jul 3 04:30:11 saruman xapi: [debug||29333 /var/lib/xcp/xapi|SR.set_virtual_allocation D:14eb2cb1a835|redo_debug] Write was successful Jul 3 04:30:11 saruman xapi: [debug||29333 /var/lib/xcp/xapi|SR.set_virtual_allocation D:14eb2cb1a835|redo_debug] Xapi_database__Redo_log.healthy Jul 3 04:30:11 saruman xapi: [debug||29333 /var/lib/xcp/xapi|SR.set_virtual_allocation D:14eb2cb1a835|redo_debug] Xapi_database__Redo_log.can_connect_fn Jul 3 04:30:11 saruman xapi: [ info||29331 |sm_exec D:f548aa962a5a|xapi_session] Session.destroy trackid=044d562d253caff4cbd0d76f8bb65cd9 Jul 3 04:30:11 saruman xapi: [debug||29331 |OpaqueRef:03361ab5-f886-e53b-8e84-1eb561e1287c|dummytaskhelper] task SR.stat D:64215b068f3e created by task R:03361ab5f886 Jul 3 04:30:11 saruman xapi: [debug||29331 |SR.stat D:64215b068f3e|sm] SM iso sr_update sr=OpaqueRef:16725e54-2f51-9bcc-0a1b-31847b9d2bfb Jul 3 04:30:11 saruman xapi: [ info||29331 |sm_exec D:979958d19c70|xapi_session] Session.create trackid=f65cd8f484f76de27013357658c6eb2f pool=false uname= originator=xapi is_local_superuser=true auth_user_s$ Jul 3 04:30:11 saruman xapi: [debug||29335 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:pool.get_all D:d273946d61f0 created by task D:979958d19c70 Jul 3 04:30:11 saruman xapi: [debug||20788 HTTPS 192.168.11.80->:::80|post_root|dummytaskhelper] task dispatch:event.from D:c9d0729e2ead created by task D:2339f3bbdbf5 Jul 3 04:30:11 saruman xapi: [ info||29331 |sm_exec D:979958d19c70|xapi_session] Session.destroy trackid=f65cd8f484f76de27013357658c6eb2f Jul 3 04:30:11 saruman xapi: [debug||29330 /var/lib/xcp/xapi|SR.scan R:03361ab5f886|xapi_sr] Xapi_sr.scan.(fun).scan_rec no change detected, updating VDIs Jul 3 04:30:11 saruman xapi: [debug||29330 /var/lib/xcp/xapi|SR.scan R:03361ab5f886|redo_debug] Write was successful Jul 3 04:30:11 saruman xapi: [debug||29330 /var/lib/xcp/xapi|SR.scan R:03361ab5f886|redo_debug] Xapi_database__Redo_log.healthy Jul 3 04:30:11 saruman xapi: [debug||29330 /var/lib/xcp/xapi|SR.scan R:03361ab5f886|redo_debug] Xapi_database__Redo_log.can_connect_fn Jul 3 04:30:11 saruman xapi: [debug||29330 /var/lib/xcp/xapi|SR.scan R:03361ab5f886|message_forwarding] Unmarking SR after SR.scan (task=OpaqueRef:03361ab5-f886-e53b-8e84-1eb561e1287c) Jul 3 04:30:11 saruman xapi: [debug||29337 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:session.logout D:84e563dfc31c created by task D:087ea22e0ee5 Jul 3 04:30:11 saruman xapi: [ info||29337 /var/lib/xcp/xapi|session.logout D:671035149d08|xapi_session] Session.destroy trackid=5c51ddc5b8505a581894127d43e2343d Jul 3 04:30:11 saruman xapi: [debug||29327 |scan one D:087ea22e0ee5|xapi_sr] Scan of SR fd8042bf-61a9-e2cb-09e8-b6ea67086b15 complete. Jul 3 04:30:13 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|helpers] about to call script without a timeout: /usr/libexec/xapi/cluster-stack/xhad/ha_query_liveset Jul 3 04:30:13 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha] Liveset: online 8c67881d-e100-4a02-9e8d-98aac410e6b0 [ L A ]; aae1f2ab-1f2f-4a38-af90-97d850a2caaf [*LM A ]; Jul 3 04:30:13 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha] Processing warnings Jul 3 04:30:13 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha] Done with warnings Jul 3 04:30:13 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha_vm_failover] restart_auto_run_vms called Jul 3 04:30:13 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha_vm_failover] Setting all VMs running or paused to Halted Jul 3 04:30:13 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha_vm_failover] Protected VMs: [ ] Jul 3 04:30:13 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha_vm_failover] Restart plan for non-agile offline VMs: [ ] Jul 3 04:30:13 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha_vm_failover] Planning configuration for offline agile VMs = { total_hosts = 2; num_failures = 1; hosts = [ 4c084741 (ga$ Jul 3 04:30:13 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha_vm_failover] Computing a specific plan for the failure of VMs: [ ] Jul 3 04:30:13 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha_vm_failover] Restart plan for agile offline VMs: [ ] Jul 3 04:30:13 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha_vm_failover] Planning configuration for future failures = { total_hosts = 2; num_failures = 1; hosts = [ 4c084741 (gand$ Jul 3 04:30:13 saruman xapi: [debug||29344 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:session.slave_login D:30e665d47312 created by task D:4f75c83bbba0 Jul 3 04:30:13 saruman xapi: [ info||29344 /var/lib/xcp/xapi|session.slave_login D:21b46cc8b54f|xapi_session] Session.create trackid=b76a7fa2423b0b14608baee90f15e15e pool=true uname= originator=xapi is_loca$ Jul 3 04:30:13 saruman xapi: [debug||29345 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:pool.get_all D:fc04a18d7e57 created by task D:21b46cc8b54f Jul 3 04:30:13 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha_vm_failover] Processing 0 parallel groups Jul 3 04:30:13 saruman xapi: message repeated 2 times: [ [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha_vm_failover] Processing 0 parallel groups] Jul 3 04:30:13 saruman xapi: [debug||29346 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:session.logout D:7306f43e5ff5 created by task D:4f75c83bbba0 Jul 3 04:30:13 saruman xapi: [ info||29346 /var/lib/xcp/xapi|session.logout D:4f9ee845e8be|xapi_session] Session.destroy trackid=b76a7fa2423b0b14608baee90f15e15e Jul 3 04:30:13 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha] Network peers = [8c67881d-e100-4a02-9e8d-98aac410e6b0;aae1f2ab-1f2f-4a38-af90-97d850a2caaf] Jul 3 04:30:13 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha] Network peers = [8c67881d-e100-4a02-9e8d-98aac410e6b0;aae1f2ab-1f2f-4a38-af90-97d850a2caaf] Jul 3 04:30:15 saruman xapi: [debug||29347 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:session.logout D:fa553c2ea7a7 created by task D:823ea5ff66e2 Jul 3 04:30:15 saruman xapi: [ info||29347 /var/lib/xcp/xapi|session.logout D:1c60df689263|xapi_session] Session.destroy trackid=fdb713b419cb45f17706d387f842a09b Jul 3 04:30:15 saruman xapi: [debug||29348 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:session.slave_login D:0e0359d0b501 created by task D:823ea5ff66e2 Jul 3 04:30:15 saruman xapi: [ info||29348 /var/lib/xcp/xapi|session.slave_login D:c9db255a135f|xapi_session] Session.create trackid=ca5b0ada69a22af5dbb29ca9b62ecff4 pool=true uname= originator=xapi is_loca$ Jul 3 04:30:15 saruman xapi: [debug||29349 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:pool.get_all D:befeaad605d2 created by task D:c9db255a135f Jul 3 04:30:16 saruman xapi: [debug||29350 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:event.from D:3e3548712fe7 created by task D:823ea5ff66e2 Jul 3 04:30:29 saruman xapi: [debug||251 |xapi events D:bc2806bdd685|dummytaskhelper] task timeboxed_rpc D:61f4d39155a3 created by task D:bc2806bdd685 Jul 3 04:30:29 saruman xapi: [debug||29351 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:event.from D:61f65e9b2fe6 created by task D:bc2806bdd685 Jul 3 04:30:33 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|helpers] about to call script without a timeout: /usr/libexec/xapi/cluster-stack/xhad/ha_query_liveset Jul 3 04:30:33 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha] Liveset: online 8c67881d-e100-4a02-9e8d-98aac410e6b0 [ L A ]; aae1f2ab-1f2f-4a38-af90-97d850a2caaf [*LM A ]; Jul 3 04:30:33 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha] Processing warnings Jul 3 04:30:33 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha] Done with warnings Jul 3 04:30:33 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha_vm_failover] restart_auto_run_vms called Jul 3 04:30:33 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha_vm_failover] Setting all VMs running or paused to Halted Jul 3 04:30:33 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha_vm_failover] Protected VMs: [ ] Jul 3 04:30:33 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha_vm_failover] Restart plan for non-agile offline VMs: [ ] Jul 3 04:30:33 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha_vm_failover] Planning configuration for offline agile VMs = { total_hosts = 2; num_failures = 1; hosts = [ 4c084741 (ga$ Jul 3 04:30:33 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha_vm_failover] Computing a specific plan for the failure of VMs: [ ] Jul 3 04:30:33 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha_vm_failover] Restart plan for agile offline VMs: [ ] Jul 3 04:30:33 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha_vm_failover] Planning configuration for future failures = { total_hosts = 2; num_failures = 1; hosts = [ 4c084741 (gand$ Jul 3 04:30:33 saruman xapi: [debug||29352 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:session.slave_login D:256696960225 created by task D:4f75c83bbba0 Jul 3 04:30:33 saruman xapi: [ info||29352 /var/lib/xcp/xapi|session.slave_login D:291846df7632|xapi_session] Session.create trackid=a4bc39aa98c4eb0d44992fdcd6b9ce69 pool=true uname= originator=xapi is_loca$ Jul 3 04:30:33 saruman xapi: [debug||29353 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:pool.get_all D:26a04c1f2231 created by task D:291846df7632 Jul 3 04:30:33 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha_vm_failover] Processing 0 parallel groups Jul 3 04:30:33 saruman xapi: message repeated 2 times: [ [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha_vm_failover] Processing 0 parallel groups] Jul 3 04:30:33 saruman xapi: [debug||29354 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:session.logout D:5b5f755054e0 created by task D:4f75c83bbba0 Jul 3 04:30:33 saruman xapi: [ info||29354 /var/lib/xcp/xapi|session.logout D:ef77f285b33b|xapi_session] Session.destroy trackid=a4bc39aa98c4eb0d44992fdcd6b9ce69 Jul 3 04:30:33 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha] Network peers = [8c67881d-e100-4a02-9e8d-98aac410e6b0;aae1f2ab-1f2f-4a38-af90-97d850a2caaf] Jul 3 04:30:33 saruman xapi: [debug||1420 ha_monitor|HA monitor D:4f75c83bbba0|xapi_ha] Network peers = [8c67881d-e100-4a02-9e8d-98aac410e6b0;aae1f2ab-1f2f-4a38-af90-97d850a2caaf] Jul 3 04:30:36 saruman xapi: [ info||29355 /var/lib/xcp/xapi|post_cli|cli] xe host-ha-xapi-healthcheck username=root password=(omitted) Jul 3 04:30:36 saruman xapi: [debug||29355 /var/lib/xcp/xapi|session.slave_local_login_with_password D:39c20ac082e0|xapi_session] Add session to local storage Jul 3 04:30:41 saruman xapi: [debug||253 scanning_thread|SR scanner D:326d57d887b1|xapi_sr] Automatically scanning SRs = [ OpaqueRef:16725e54-2f51-9bcc-0a1b-31847b9d2bfb ] Jul 3 04:30:41 saruman xapi: [debug||29357 ||dummytaskhelper] task scan one D:ce353e75a70c created by task D:326d57d887b1 Jul 3 04:30:41 saruman xapi: [debug||29358 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:session.slave_login D:7c48eaa98a3b created by task D:ce353e75a70c Jul 3 04:30:41 saruman xapi: [ info||29358 /var/lib/xcp/xapi|session.slave_login D:421b8d42f22d|xapi_session] Session.create trackid=9b0008cddce78be0d1a8a89835965cf6 pool=true uname= originator=xapi is_loca$ Jul 3 04:30:41 saruman xapi: [debug||29359 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:pool.get_all D:2b5052197a9e created by task D:421b8d42f22d Jul 3 04:30:41 saruman xapi: [debug||29360 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:SR.scan D:52cfde4ee7ea created by task D:ce353e75a70c Jul 3 04:30:41 saruman xapi: [ info||29360 /var/lib/xcp/xapi|dispatch:SR.scan D:52cfde4ee7ea|taskhelper] task SR.scan R:b36a07fe474e (uuid:7c9dcc95-429c-3cbc-6599-87bc66e93af6) created (trackid=9b0008cddce7$ Jul 3 04:30:41 saruman xapi: [debug||29360 /var/lib/xcp/xapi|SR.scan R:b36a07fe474e|message_forwarding] SR.scan: SR = 'fd8042bf-61a9-e2cb-09e8-b6ea67086b15 (T1_ISO_test)' Jul 3 04:30:41 saruman xapi: [debug||29360 /var/lib/xcp/xapi|SR.scan R:b36a07fe474e|message_forwarding] Marking SR for SR.scan (task=OpaqueRef:b36a07fe-474e-42d9-b3f4-e4cf98cf5381) Jul 3 04:30:41 saruman xapi: [ info||29360 /var/lib/xcp/xapi|OpaqueRef:b36a07fe-474e-42d9-b3f4-e4cf98cf5381|mux] SR.scan2 dbg:OpaqueRef:b36a07fe-474e-42d9-b3f4-e4cf98cf5381 sr:fd8042bf-61a9-e2cb-09e8-b6ea67$ Jul 3 04:30:41 saruman xapi: [ info||29361 |OpaqueRef:b36a07fe-474e-42d9-b3f4-e4cf98cf5381|Storage_smapiv1_wrapper] SR.scan2 dbg:OpaqueRef:b36a07fe-474e-42d9-b3f4-e4cf98cf5381 sr:fd8042bf-61a9-e2cb-09e8-b6e$ Jul 3 04:30:41 saruman xapi: [debug||29361 |OpaqueRef:b36a07fe-474e-42d9-b3f4-e4cf98cf5381|dummytaskhelper] task SR.scan D:0ff27a344594 created by task R:b36a07fe474e Jul 3 04:30:41 saruman xapi: [debug||29361 |SR.scan D:0ff27a344594|sm] SM iso sr_scan sr=OpaqueRef:16725e54-2f51-9bcc-0a1b-31847b9d2bfb Jul 3 04:30:41 saruman xapi: [ info||29361 |sm_exec D:f4b42249db30|xapi_session] Session.create trackid=7d4a7ec966034082d042dbd75476be23 pool=false uname= originator=xapi is_local_superuser=true auth_user_s$ Jul 3 04:30:41 saruman xapi: [debug||29362 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:pool.get_all D:b21f37b14caf created by task D:f4b42249db30 Jul 3 04:30:41 saruman xapi: [debug||29363 /var/lib/xcp/xapi|SR.set_virtual_allocation D:b15ae3e066f7|redo_debug] Write was successful Jul 3 04:30:41 saruman xapi: [debug||29363 /var/lib/xcp/xapi|SR.set_virtual_allocation D:b15ae3e066f7|redo_debug] Xapi_database__Redo_log.healthy Jul 3 04:30:41 saruman xapi: [debug||29363 /var/lib/xcp/xapi|SR.set_virtual_allocation D:b15ae3e066f7|redo_debug] Xapi_database__Redo_log.can_connect_fn Jul 3 04:30:41 saruman xapi: [ info||29361 |sm_exec D:f4b42249db30|xapi_session] Session.destroy trackid=7d4a7ec966034082d042dbd75476be23 Jul 3 04:30:41 saruman xapi: [debug||29361 |OpaqueRef:b36a07fe-474e-42d9-b3f4-e4cf98cf5381|dummytaskhelper] task SR.stat D:159d91e07fc2 created by task R:b36a07fe474e Jul 3 04:30:41 saruman xapi: [debug||29361 |SR.stat D:159d91e07fc2|sm] SM iso sr_update sr=OpaqueRef:16725e54-2f51-9bcc-0a1b-31847b9d2bfb Jul 3 04:30:41 saruman xapi: [ info||29361 |sm_exec D:25319819b26e|xapi_session] Session.create trackid=ec954d74b101b2a193745267c4708e2d pool=false uname= originator=xapi is_local_superuser=true auth_user_s$ Jul 3 04:30:41 saruman xapi: [debug||29364 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:pool.get_all D:7595297ca928 created by task D:25319819b26e Jul 3 04:30:41 saruman xapi: [ info||29361 |sm_exec D:25319819b26e|xapi_session] Session.destroy trackid=ec954d74b101b2a193745267c4708e2d Jul 3 04:30:41 saruman xapi: [debug||29360 /var/lib/xcp/xapi|SR.scan R:b36a07fe474e|xapi_sr] Xapi_sr.scan.(fun).scan_rec no change detected, updating VDIs Jul 3 04:30:41 saruman xapi: [debug||29360 /var/lib/xcp/xapi|SR.scan R:b36a07fe474e|redo_debug] Write was successful Jul 3 04:30:41 saruman xapi: [debug||29360 /var/lib/xcp/xapi|SR.scan R:b36a07fe474e|redo_debug] Xapi_database__Redo_log.healthy Jul 3 04:30:41 saruman xapi: [debug||29360 /var/lib/xcp/xapi|SR.scan R:b36a07fe474e|redo_debug] Xapi_database__Redo_log.can_connect_fn Jul 3 04:30:41 saruman xapi: [debug||29360 /var/lib/xcp/xapi|SR.scan R:b36a07fe474e|message_forwarding] Unmarking SR after SR.scan (task=OpaqueRef:b36a07fe-474e-42d9-b3f4-e4cf98cf5381) Jul 3 04:30:41 saruman xapi: [debug||29366 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:session.logout D:87639fdc3f1b created by task D:ce353e75a70c Jul 3 04:30:41 saruman xapi: [ info||29366 /var/lib/xcp/xapi|session.logout D:47505cbbd073|xapi_session] Session.destroy trackid=9b0008cddce78be0d1a8a89835965cf6 Jul 3 04:30:41 saruman xapi: [debug||29357 |scan one D:ce353e75a70c|xapi_sr] Scan of SR fd8042bf-61a9-e2cb-09e8-b6ea67086b15 complete. -
the log @ 04:35:11 to 04:35:57 is + 300kb
Is there anything I can sort out -
04:35:11
Jul 3 04:35:11 saruman xapi: [debug||253 scanning_thread|SR scanner D:326d57d887b1|xapi_sr] Automatically scanning SRs = [ OpaqueRef:16725e54-2f51-9bcc-0a1b-31847b9d2bfb ] Jul 3 04:35:11 saruman xapi: [debug||29568 ||dummytaskhelper] task scan one D:732f75985406 created by task D:326d57d887b1 Jul 3 04:35:11 saruman xapi: [debug||29569 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:session.slave_login D:eccbbe50488c created by task D:732f75985406 Jul 3 04:35:11 saruman xapi: [ info||29569 /var/lib/xcp/xapi|session.slave_login D:cc07678de121|xapi_session] Session.create trackid=3bd666ff307e18fa86ce028a05437c1b pool=true uname= originator=xapi is_loca$ Jul 3 04:35:11 saruman xapi: [debug||29570 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:pool.get_all D:0fd564ae5c24 created by task D:cc07678de121 Jul 3 04:35:11 saruman xapi: [debug||29571 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:SR.scan D:9dd57167ef24 created by task D:732f75985406 Jul 3 04:35:11 saruman xapi: [ info||29571 /var/lib/xcp/xapi|dispatch:SR.scan D:9dd57167ef24|taskhelper] task SR.scan R:30711df16968 (uuid:2a8220fc-6843-ae13-7934-af2faad9d716) created (trackid=3bd666ff307e$ Jul 3 04:35:11 saruman xapi: [debug||29571 /var/lib/xcp/xapi|SR.scan R:30711df16968|message_forwarding] SR.scan: SR = 'fd8042bf-61a9-e2cb-09e8-b6ea67086b15 (T1_ISO_test)' Jul 3 04:35:11 saruman xapi: [debug||29571 /var/lib/xcp/xapi|SR.scan R:30711df16968|message_forwarding] Marking SR for SR.scan (task=OpaqueRef:30711df1-6968-d3f8-5c29-47cc108f58a5) Jul 3 04:35:11 saruman xapi: [ info||29571 /var/lib/xcp/xapi|OpaqueRef:30711df1-6968-d3f8-5c29-47cc108f58a5|mux] SR.scan2 dbg:OpaqueRef:30711df1-6968-d3f8-5c29-47cc108f58a5 sr:fd8042bf-61a9-e2cb-09e8-b6ea67$ Jul 3 04:35:11 saruman xapi: [ info||29572 |OpaqueRef:30711df1-6968-d3f8-5c29-47cc108f58a5|Storage_smapiv1_wrapper] SR.scan2 dbg:OpaqueRef:30711df1-6968-d3f8-5c29-47cc108f58a5 sr:fd8042bf-61a9-e2cb-09e8-b6e$ Jul 3 04:35:11 saruman xapi: [debug||29572 |OpaqueRef:30711df1-6968-d3f8-5c29-47cc108f58a5|dummytaskhelper] task SR.scan D:5930d0b18dda created by task R:30711df16968 Jul 3 04:35:11 saruman xapi: [debug||29572 |SR.scan D:5930d0b18dda|sm] SM iso sr_scan sr=OpaqueRef:16725e54-2f51-9bcc-0a1b-31847b9d2bfb Jul 3 04:35:11 saruman xapi: [ info||29572 |sm_exec D:cdde671c2793|xapi_session] Session.create trackid=603446d3a4f6757a43d68053f52d381d pool=false uname= originator=xapi is_local_superuser=true auth_user_s$ Jul 3 04:35:11 saruman xapi: [debug||29573 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:pool.get_all D:f3490996e6d0 created by task D:cdde671c2793 Jul 3 04:35:11 saruman xapi: [debug||29574 /var/lib/xcp/xapi|SR.set_virtual_allocation D:1eeb803b2ec7|redo_debug] Write was successful Jul 3 04:35:11 saruman xapi: [debug||29574 /var/lib/xcp/xapi|SR.set_virtual_allocation D:1eeb803b2ec7|redo_debug] Xapi_database__Redo_log.healthy Jul 3 04:35:11 saruman xapi: [debug||29574 /var/lib/xcp/xapi|SR.set_virtual_allocation D:1eeb803b2ec7|redo_debug] Xapi_database__Redo_log.can_connect_fn Jul 3 04:35:11 saruman xapi: [ info||29572 |sm_exec D:cdde671c2793|xapi_session] Session.destroy trackid=603446d3a4f6757a43d68053f52d381d Jul 3 04:35:11 saruman xapi: [debug||29572 |OpaqueRef:30711df1-6968-d3f8-5c29-47cc108f58a5|dummytaskhelper] task SR.stat D:a6701a0ec320 created by task R:30711df16968 Jul 3 04:35:11 saruman xapi: [debug||29572 |SR.stat D:a6701a0ec320|sm] SM iso sr_update sr=OpaqueRef:16725e54-2f51-9bcc-0a1b-31847b9d2bfb Jul 3 04:35:11 saruman xapi: [ info||29572 |sm_exec D:ceb705d62eae|xapi_session] Session.create trackid=e3c583021d6b31a31247294476f0db00 pool=false uname= originator=xapi is_local_superuser=true auth_user_s$ Jul 3 04:35:11 saruman xapi: [debug||29575 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:pool.get_all D:59518d9a8e14 created by task D:ceb705d62eae Jul 3 04:35:11 saruman xapi: [debug||29522 HTTPS 192.168.11.80->:::80|post_root|dummytaskhelper] task dispatch:event.from D:01634ea2dc87 created by task D:2339f3bbdbf5 Jul 3 04:35:11 saruman xapi: [ info||29572 |sm_exec D:ceb705d62eae|xapi_session] Session.destroy trackid=e3c583021d6b31a31247294476f0db00 Jul 3 04:35:11 saruman xapi: [debug||29571 /var/lib/xcp/xapi|SR.scan R:30711df16968|xapi_sr] Xapi_sr.scan.(fun).scan_rec no change detected, updating VDIs Jul 3 04:35:11 saruman xapi: [debug||29571 /var/lib/xcp/xapi|SR.scan R:30711df16968|redo_debug] Write was successful Jul 3 04:35:11 saruman xapi: [debug||29571 /var/lib/xcp/xapi|SR.scan R:30711df16968|redo_debug] Xapi_database__Redo_log.healthy Jul 3 04:35:11 saruman xapi: [debug||29571 /var/lib/xcp/xapi|SR.scan R:30711df16968|redo_debug] Xapi_database__Redo_log.can_connect_fn Jul 3 04:35:11 saruman xapi: [debug||29571 /var/lib/xcp/xapi|SR.scan R:30711df16968|message_forwarding] Unmarking SR after SR.scan (task=OpaqueRef:30711df1-6968-d3f8-5c29-47cc108f58a5) Jul 3 04:35:11 saruman xapi: [debug||29578 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:session.logout D:a2c2abbfb834 created by task D:732f75985406 Jul 3 04:35:11 saruman xapi: [ info||29578 /var/lib/xcp/xapi|session.logout D:a86923f19a9e|xapi_session] Session.destroy trackid=3bd666ff307e18fa86ce028a05437c1b Jul 3 04:35:11 saruman xapi: [debug||29568 |scan one D:732f75985406|xapi_sr] Scan of SR fd8042bf-61a9-e2cb-09e8-b6ea67086b15 complete. -
04:35:12
Jul 3 04:35:12 saruman xapi: [debug||29579 HTTPS 192.168.11.104->:::80|session.login_with_password D:078b8e80c48d|xapi_session] Success: local auth, user root from HTTP request from Internet with User-Agent$ Jul 3 04:35:12 saruman xapi: [ info||29579 HTTPS 192.168.11.104->:::80|session.login_with_password D:078b8e80c48d|xapi_session] Session.create trackid=312991ac2a491678ffbd03d423ed0141 pool=false uname=root $ Jul 3 04:35:12 saruman xapi: [debug||29580 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:pool.get_all D:bc2edf3c8615 created by task D:078b8e80c48d Jul 3 04:35:12 saruman xapi: [debug||29582 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:session.logout D:69563c555812 created by task D:823ea5ff66e2 Jul 3 04:35:12 saruman xapi: [ info||29582 /var/lib/xcp/xapi|session.logout D:3070e3db5da9|xapi_session] Session.destroy trackid=48e113dd5c7a1d45458e1d2b92601693 Jul 3 04:35:12 saruman xapi: [debug||29583 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:session.slave_login D:f633debe7850 created by task D:823ea5ff66e2 Jul 3 04:35:12 saruman xapi: [ info||29583 /var/lib/xcp/xapi|session.slave_login D:e9b0235f0e4a|xapi_session] Session.create trackid=ca2803ef4e7083f4747a48db63c177e6 pool=true uname= originator=xapi is_loca$ Jul 3 04:35:12 saruman xapi: [debug||29584 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:pool.get_all D:26e00eb4d36e created by task D:e9b0235f0e4a Jul 3 04:35:12 saruman xapi: [debug||29585 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:event.from D:78809790a29d created by task D:823ea5ff66e2 Jul 3 04:35:12 saruman xapi: [debug||29579 HTTPS 192.168.11.104->:::80|VM.remove_from_blocked_operations R:cbfa771b26b7|audit] VM.remove_from_blocked_operations: self = '9568a891-c547-964e-5efb-9f793ac7fb42$ Jul 3 04:35:12 saruman xapi: [debug||29579 HTTPS 192.168.11.104->:::80|VM.remove_from_blocked_operations R:cbfa771b26b7|xapi_vm] Xapi_vm.remove_from_blocked_operations Jul 3 04:35:12 saruman xapi: [debug||29581 HTTPS 192.168.11.104->:::80|VM.remove_from_blocked_operations R:59870af6f27b|audit] VM.remove_from_blocked_operations: self = '9568a891-c547-964e-5efb-9f793ac7fb42$ Jul 3 04:35:12 saruman xapi: [debug||29581 HTTPS 192.168.11.104->:::80|VM.remove_from_blocked_operations R:59870af6f27b|xapi_vm] Xapi_vm.remove_from_blocked_operations Jul 3 04:35:12 saruman xapi: [debug||29586 HTTPS 192.168.11.104->:::80|VM.add_to_blocked_operations R:120f9900abf1|audit] VM.add_to_blocked_operations: self = '9568a891-c547-964e-5efb-9f793ac7fb42 (XO-Sauro$ Jul 3 04:35:12 saruman xapi: [debug||29586 HTTPS 192.168.11.104->:::80|VM.add_to_blocked_operations R:120f9900abf1|xapi_vm] Xapi_vm.add_to_blocked_operations Jul 3 04:35:12 saruman xapi: [debug||29586 HTTPS 192.168.11.104->:::80|VM.add_to_blocked_operations R:120f9900abf1|redo_debug] Write was successful Jul 3 04:35:12 saruman xapi: [debug||29586 HTTPS 192.168.11.104->:::80|VM.add_to_blocked_operations R:120f9900abf1|redo_debug] Xapi_database__Redo_log.healthy Jul 3 04:35:12 saruman xapi: [debug||29586 HTTPS 192.168.11.104->:::80|VM.add_to_blocked_operations R:120f9900abf1|redo_debug] Xapi_database__Redo_log.can_connect_fn Jul 3 04:35:12 saruman xapi: [debug||29579 HTTPS 192.168.11.104->:::80|VM.add_to_blocked_operations R:c0c78557699e|audit] VM.add_to_blocked_operations: self = '9568a891-c547-964e-5efb-9f793ac7fb42 (XO-Sauro$ Jul 3 04:35:12 saruman xapi: [debug||29579 HTTPS 192.168.11.104->:::80|VM.add_to_blocked_operations R:c0c78557699e|xapi_vm] Xapi_vm.add_to_blocked_operations Jul 3 04:35:12 saruman xapi: [debug||251 |xapi events D:bc2806bdd685|xenops] Event on VM 9568a891-c547-964e-5efb-9f793ac7fb42; resident_here = true Jul 3 04:35:12 saruman xapi: [debug||29579 HTTPS 192.168.11.104->:::80|VM.add_to_blocked_operations R:c0c78557699e|redo_debug] Write was successful Jul 3 04:35:12 saruman xapi: [debug||29579 HTTPS 192.168.11.104->:::80|VM.add_to_blocked_operations R:c0c78557699e|redo_debug] Xapi_database__Redo_log.healthy Jul 3 04:35:12 saruman xapi: [debug||29579 HTTPS 192.168.11.104->:::80|VM.add_to_blocked_operations R:c0c78557699e|redo_debug] Xapi_database__Redo_log.can_connect_fn Jul 3 04:35:12 saruman xapi: [debug||29581 HTTPS 192.168.11.104->:::80|VM.remove_from_blocked_operations R:a1c90fe4b993|audit] VM.remove_from_blocked_operations: self = '8353b44b-86cb-475b-e730-97f7fa7bacc6$ Jul 3 04:35:12 saruman xapi: [debug||29587 HTTPS 192.168.11.104->:::80|VM.remove_from_blocked_operations R:864e0196124f|audit] VM.remove_from_blocked_operations: self = '8353b44b-86cb-475b-e730-97f7fa7bacc6$ Jul 3 04:35:12 saruman xapi: [debug||29581 HTTPS 192.168.11.104->:::80|VM.remove_from_blocked_operations R:a1c90fe4b993|xapi_vm] Xapi_vm.remove_from_blocked_operations Jul 3 04:35:12 saruman xapi: [debug||29587 HTTPS 192.168.11.104->:::80|VM.remove_from_blocked_operations R:864e0196124f|xapi_vm] Xapi_vm.remove_from_blocked_operations Jul 3 04:35:12 saruman xapi: [debug||251 |xapi events D:bc2806bdd685|xenops] xapi_cache: not updating cache for 9568a891-c547-964e-5efb-9f793ac7fb42 Jul 3 04:35:12 saruman xapi: [debug||251 |xapi events D:bc2806bdd685|dummytaskhelper] task timeboxed_rpc D:49d7209c4cec created by task D:bc2806bdd685 Jul 3 04:35:12 saruman xapi: [debug||29586 HTTPS 192.168.11.104->:::80|VM.add_to_blocked_operations R:b8c16837eac3|audit] VM.add_to_blocked_operations: self = '8353b44b-86cb-475b-e730-97f7fa7bacc6 (2-LMDE7)$ Jul 3 04:35:12 saruman xapi: [debug||29586 HTTPS 192.168.11.104->:::80|VM.add_to_blocked_operations R:b8c16837eac3|xapi_vm] Xapi_vm.add_to_blocked_operations Jul 3 04:35:12 saruman xapi: [debug||29616 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:event.from D:41bf54393b78 created by task D:bc2806bdd685 Jul 3 04:35:12 saruman xapi: [debug||29586 HTTPS 192.168.11.104->:::80|VM.add_to_blocked_operations R:b8c16837eac3|redo_debug] Write was successful Jul 3 04:35:12 saruman xapi: [debug||29586 HTTPS 192.168.11.104->:::80|VM.add_to_blocked_operations R:b8c16837eac3|redo_debug] Xapi_database__Redo_log.healthy Jul 3 04:35:12 saruman xapi: [debug||29586 HTTPS 192.168.11.104->:::80|VM.add_to_blocked_operations R:b8c16837eac3|redo_debug] Xapi_database__Redo_log.can_connect_fn Jul 3 04:35:12 saruman xapi: [debug||29581 HTTPS 192.168.11.104->:::80|VM.add_to_blocked_operations R:4f271f2de8d1|audit] VM.add_to_blocked_operations: self = '8353b44b-86cb-475b-e730-97f7fa7bacc6 (2-LMDE7)$ Jul 3 04:35:12 saruman xapi: [debug||29581 HTTPS 192.168.11.104->:::80|VM.add_to_blocked_operations R:4f271f2de8d1|xapi_vm] Xapi_vm.add_to_blocked_operations Jul 3 04:35:12 saruman xapi: [debug||251 |xapi events D:bc2806bdd685|xenops] Event on VM 9568a891-c547-964e-5efb-9f793ac7fb42; resident_here = true Jul 3 04:35:12 saruman xapi: [debug||29581 HTTPS 192.168.11.104->:::80|VM.add_to_blocked_operations R:4f271f2de8d1|redo_debug] Write was successful Jul 3 04:35:12 saruman xapi: [debug||29581 HTTPS 192.168.11.104->:::80|VM.add_to_blocked_operations R:4f271f2de8d1|redo_debug] Xapi_database__Redo_log.healthy Jul 3 04:35:12 saruman xapi: [debug||29581 HTTPS 192.168.11.104->:::80|VM.add_to_blocked_operations R:4f271f2de8d1|redo_debug] Xapi_database__Redo_log.can_connect_fn Jul 3 04:35:12 saruman xapi: [debug||251 |xapi events D:bc2806bdd685|xenops] xapi_cache: not updating cache for 9568a891-c547-964e-5efb-9f793ac7fb42 Jul 3 04:35:12 saruman xapi: [debug||251 |xapi events D:bc2806bdd685|dummytaskhelper] task timeboxed_rpc D:606238890c31 created by task D:bc2806bdd685 Jul 3 04:35:12 saruman xapi: [debug||29617 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:event.from D:aa12a2dc6e7f created by task D:bc2806bdd685 Jul 3 04:35:12 saruman xapi: [debug||29579 HTTPS 192.168.11.104->:::80|VM.remove_from_other_config D:09c0ab21bf75|audit] VM.remove_from_other_config: self = '9568a891-c547-964e-5efb-9f793ac7fb42 (XO-Sauron)$ Jul 3 04:35:12 saruman xapi: [debug||29581 HTTPS 192.168.11.104->:::80|VM.remove_from_other_config D:21199f16e114|audit] VM.remove_from_other_config: self = '9568a891-c547-964e-5efb-9f793ac7fb42 (XO-Sauron)$ Jul 3 04:35:12 saruman xapi: [debug||29588 HTTPS 192.168.11.104->:::80|VM.remove_from_other_config D:a4bd602cbe8e|audit] VM.remove_from_other_config: self = '9568a891-c547-964e-5efb-9f793ac7fb42 (XO-Sauron)$ Jul 3 04:35:12 saruman xapi: [debug||29587 HTTPS 192.168.11.104->:::80|VM.remove_from_other_config D:d1c1276459e6|audit] VM.remove_from_other_config: self = '9568a891-c547-964e-5efb-9f793ac7fb42 (XO-Sauron)$ Jul 3 04:35:12 saruman xapi: [debug||29589 HTTPS 192.168.11.104->:::80|VM.remove_from_other_config D:c0de975ab044|audit] VM.remove_from_other_config: self = '9568a891-c547-964e-5efb-9f793ac7fb42 (XO-Sauron)$ Jul 3 04:35:12 saruman xapi: [debug||29594 :::80|dispatch:VDI.remove_from_other_config D:055791cdfc68|api_effect] VDI.remove_from_other_config Jul 3 04:35:12 saruman xapi: [debug||29591 HTTPS 192.168.11.104->:::80|VM.remove_from_other_config D:f790effaa602|audit] VM.remove_from_other_config: self = '9568a891-c547-964e-5efb-9f793ac7fb42 (XO-Sauron)$ Jul 3 04:35:12 saruman xapi: [debug||29593 :::80|dispatch:VDI.remove_from_other_config D:2bfdc6504ebb|api_effect] VDI.remove_from_other_config Jul 3 04:35:12 saruman xapi: [debug||29590 HTTPS 192.168.11.104->:::80|VM.remove_from_other_config D:d79e6e4a5136|audit] VM.remove_from_other_config: self = '9568a891-c547-964e-5efb-9f793ac7fb42 (XO-Sauron)$ Jul 3 04:35:12 saruman xapi: [debug||29592 HTTPS 192.168.11.104->:::80|VM.remove_from_other_config D:8ee15c17ea09|audit] VM.remove_from_other_config: self = '9568a891-c547-964e-5efb-9f793ac7fb42 (XO-Sauron)$ Jul 3 04:35:12 saruman xapi: [debug||29598 :::80|dispatch:VDI.remove_from_other_config D:e3b2d69ca32b|api_effect] VDI.remove_from_other_config Jul 3 04:35:12 saruman xapi: [debug||29597 :::80|dispatch:VDI.remove_from_other_config D:06d05c0b1461|api_effect] VDI.remove_from_other_config Jul 3 04:35:12 saruman xapi: [debug||29595 :::80|dispatch:VDI.remove_from_other_config D:db62dc7de8f4|api_effect] VDI.remove_from_other_config Jul 3 04:35:12 saruman xapi: [debug||29600 :::80|dispatch:VDI.remove_from_other_config D:d03eeab97ea6|api_effect] VDI.remove_from_other_config Jul 3 04:35:12 saruman xapi: [debug||29599 :::80|dispatch:VDI.remove_from_other_config D:3893de8bae36|api_effect] VDI.remove_from_other_config Jul 3 04:35:12 saruman xapi: [debug||29596 :::80|dispatch:VDI.remove_from_other_config D:a5bf3ce348ca|api_effect] VDI.remove_from_other_config Jul 3 04:35:12 saruman xapi: [debug||29579 :::80|dispatch:pool.add_to_other_config D:bdfc9a522f7a|api_effect] pool.add_to_other_config Jul 3 04:35:12 saruman xapi: [debug||29579 HTTPS 192.168.11.104->:::80|pool.add_to_other_config D:0a47778fa26d|redo_debug] Write was successful Jul 3 04:35:12 saruman xapi: [debug||29579 HTTPS 192.168.11.104->:::80|pool.add_to_other_config D:0a47778fa26d|redo_debug] Xapi_database__Redo_log.healthy Jul 3 04:35:12 saruman xapi: [debug||29579 HTTPS 192.168.11.104->:::80|pool.add_to_other_config D:0a47778fa26d|redo_debug] Xapi_database__Redo_log.can_connect_fn Jul 3 04:35:12 saruman xapi: [debug||29591 HTTPS 192.168.11.104->:::80|VM.remove_from_other_config D:c4766abc27f9|audit] VM.remove_from_other_config: self = '8353b44b-86cb-475b-e730-97f7fa7bacc6 (2-LMDE7)',$ Jul 3 04:35:12 saruman xapi: [debug||29589 HTTPS 192.168.11.104->:::80|VM.remove_from_other_config D:063aa097b84d|audit] VM.remove_from_other_config: self = '8353b44b-86cb-475b-e730-97f7fa7bacc6 (2-LMDE7)',$ Jul 3 04:35:12 saruman xapi: [debug||29593 :::80|dispatch:VDI.remove_from_other_config D:f8726461e0a6|api_effect] VDI.remove_from_other_config Jul 3 04:35:12 saruman xapi: [debug||29590 HTTPS 192.168.11.104->:::80|VM.remove_from_other_config D:56a1ee681aa1|audit] VM.remove_from_other_config: self = '8353b44b-86cb-475b-e730-97f7fa7bacc6 (2-LMDE7)',$ Jul 3 04:35:12 saruman xapi: [debug||29588 HTTPS 192.168.11.104->:::80|VM.remove_from_other_config D:d0c436e970e0|audit] VM.remove_from_other_config: self = '8353b44b-86cb-475b-e730-97f7fa7bacc6 (2-LMDE7)',$ Jul 3 04:35:12 saruman xapi: [debug||29594 :::80|dispatch:VDI.remove_from_other_config D:b5d6bc3ef534|api_effect] VDI.remove_from_other_config Jul 3 04:35:12 saruman xapi: [debug||29599 :::80|dispatch:VDI.remove_from_other_config D:03ba46b0e8ef|api_effect] VDI.remove_from_other_config Jul 3 04:35:12 saruman xapi: [debug||29618 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:session.logout D:d5f8624586ad created by task D:823ea5ff66e2 Jul 3 04:35:12 saruman xapi: [ info||29618 /var/lib/xcp/xapi|session.logout D:7e639832bcac|xapi_session] Session.destroy trackid=ca2803ef4e7083f4747a48db63c177e6 Jul 3 04:35:12 saruman xapi: [debug||29598 :::80|dispatch:VDI.remove_from_other_config D:96529103281e|api_effect] VDI.remove_from_other_config Jul 3 04:35:12 saruman xapi: [debug||29595 :::80|dispatch:VDI.remove_from_other_config D:e85d4b89ad38|api_effect] VDI.remove_from_other_config Jul 3 04:35:12 saruman xapi: [debug||29587 HTTPS 192.168.11.104->:::80|event.from D:be3f60eca8bb|xapi_message] Xapi_message.get_since_for_events.(fun): cache (6778) might not contain all messages since the $ Jul 3 04:35:12 saruman xapi: [debug||29597 :::80|dispatch:VDI.remove_from_other_config D:88fc89495212|api_effect] VDI.remove_from_other_config Jul 3 04:35:12 saruman xapi: [debug||29600 :::80|dispatch:VDI.remove_from_other_config D:6a674f0efe15|api_effect] VDI.remove_from_other_config Jul 3 04:35:12 saruman xapi: [debug||29586 HTTPS 192.168.11.104->:::80|VM.remove_from_other_config D:833cf106f19c|audit] VM.remove_from_other_config: self = '8353b44b-86cb-475b-e730-97f7fa7bacc6 (2-LMDE7)',$ Jul 3 04:35:12 saruman xapi: [debug||29596 :::80|dispatch:VDI.remove_from_other_config D:9254480263a9|api_effect] VDI.remove_from_other_config Jul 3 04:35:12 saruman xapi: [debug||29581 HTTPS 192.168.11.104->:::80|VM.remove_from_other_config D:8c2599ed7ef2|audit] VM.remove_from_other_config: self = '8353b44b-86cb-475b-e730-97f7fa7bacc6 (2-LMDE7)',$ Jul 3 04:35:12 saruman xapi: [debug||29592 HTTPS 192.168.11.104->:::80|VM.remove_from_other_config D:ca1700a7e280|audit] VM.remove_from_other_config: self = '8353b44b-86cb-475b-e730-97f7fa7bacc6 (2-LMDE7)',$ Jul 3 04:35:12 saruman xapi: [debug||29579 HTTPS 192.168.11.104->:::80|VM.remove_from_other_config D:aafbe991c105|audit] VM.remove_from_other_config: self = '8353b44b-86cb-475b-e730-97f7fa7bacc6 (2-LMDE7)',$ Jul 3 04:35:12 saruman xapi: [debug||29619 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:session.slave_login D:89df7c940b75 created by task D:823ea5ff66e2 Jul 3 04:35:12 saruman xapi: [ info||29619 /var/lib/xcp/xapi|session.slave_login D:59ec45a4596a|xapi_session] Session.create trackid=dc8fda850a7364496d500cdb347f5e29 pool=true uname= originator=xapi is_loca$ Jul 3 04:35:12 saruman xapi: [debug||29620 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:pool.get_all D:a750749f3208 created by task D:59ec45a4596a Jul 3 04:35:12 saruman xapi: [debug||29522 HTTPS 192.168.11.80->:::80|post_root|dummytaskhelper] task dispatch:event.from D:40c21b705d99 created by task D:2339f3bbdbf5 Jul 3 04:35:12 saruman xapi: [debug||29621 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:event.from D:bd4ae306d733 created by task D:823ea5ff66e2 Jul 3 04:35:12 saruman xapi: [debug||29588 :::80|dispatch:pool.remove_from_other_config D:09bc5706ae58|api_effect] pool.remove_from_other_config Jul 3 04:35:12 saruman xapi: [debug||29588 HTTPS 192.168.11.104->:::80|pool.remove_from_other_config D:b878052f8693|redo_debug] Write was successful Jul 3 04:35:12 saruman xapi: [debug||29588 HTTPS 192.168.11.104->:::80|pool.remove_from_other_config D:b878052f8693|redo_debug] Xapi_database__Redo_log.healthy Jul 3 04:35:12 saruman xapi: [debug||29588 HTTPS 192.168.11.104->:::80|pool.remove_from_other_config D:b878052f8693|redo_debug] Xapi_database__Redo_log.can_connect_fn Jul 3 04:35:12 saruman xapi: [debug||29590 :::80|dispatch:pool.add_to_other_config D:606a7dcff861|api_effect] pool.add_to_other_config Jul 3 04:35:12 saruman xapi: [debug||29622 /var/lib/xcp/xapi|post_root|dummytaskhelper] task dispatch:session.logout D:40aaae606f44 created by task D:823ea5ff66e2 Jul 3 04:35:12 saruman xapi: [ info||29622 /var/lib/xcp/xapi|session.logout D:015fd09352fd|xapi_session] Session.destroy trackid=dc8fda850a7364496d500cdb347f5e29 Jul 3 04:35:12 saruman xapi: [debug||29590 HTTPS 192.168.11.104->:::80|pool.add_to_other_config D:d8968e8ce182|redo_debug] Write was successful Jul 3 04:35:12 saruman xapi: [debug||29590 HTTPS 192.168.11.104->:::80|pool.add_to_other_config D:d8968e8ce182|redo_debug] Xapi_database__Redo_log.healthy Jul 3 04:35:12 saruman xapi: [debug||29590 HTTPS 192.168.11.104->:::80|pool.add_to_other_config D:d8968e8ce182|redo_debug] Xapi_database__Redo_log.can_connect_fn
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login