XOSTOR - Tech preview
 Installation script is compatible with XCP-ng 8.2 and 8.3
Installation script is compatible with XCP-ng 8.2 and 8.3
UPDATE to sm-2.30.7-1.3.0.linstor.7
Please read this: https://xcp-ng.org/forum/topic/5361/xostor-hyperconvergence-preview/224?_=1679390249707
UPDATE from an older version (before sm-2.30.7-1.3.0.linstor.3)
Please read this: https://xcp-ng.org/forum/topic/5361/xostor-hyperconvergence-preview/177?_=1667938000897
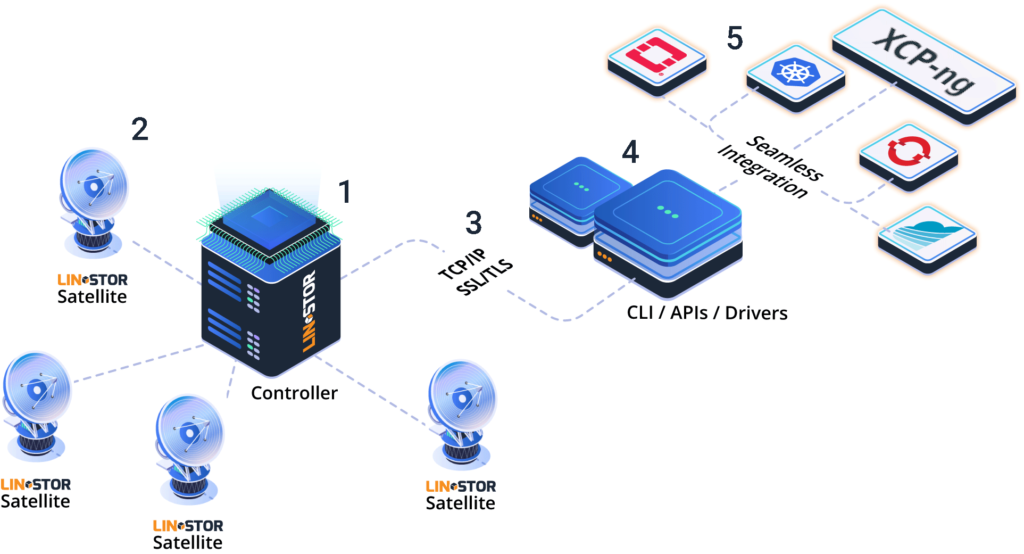
XOSTOR is a "disaggregated hyperconvergence storage solution". In plain English: you can assemble local storage of multiple hosts into one "fake" shared storage.
The key to get fast hyperconvergence is to try a different approach. We used GlusterFS for XOSAN, and it wasn't really fast for small random blocks (due to the nature of the global filesystem). But in XOSTOR, there's a catch: unlike traditional hyperconvergence, it won't create a global clustered and shared filesystem. This time, when you'll create a VM disk, it will create a "resource", that will be replicated "n" times on multiple hosts (eg twice or 3 times).
So in the end, the number of resources depends on the VM disk numbers (and snapshots).
The technology we use is not invented from scratch, we are using LINSTOR from LINBIT, based itself on DRBD. See https://linbit.com/linstor/
For you, it will be (ideally) transparent.
Ultimate goals
Our first goal here is to validate the technology at scale. If it works as we expect, then we'll add a complete automated solution and UI on top of it, and sell pro support for people who want to get a "turnkey" supported solution (a la XOA).
The manual/shell script installation as described here is meant to stay fully open/accessible with community support ")
Now I'm letting @ronan-a writing the rest of this message Thanks a lot for your hard work ")
Important
Despite we are doing intensive testing with this technology in the last 2 years (!), it was really HARD to integrate it easily into SMAPIv1 (legacy storage stack of XCP-ng). Especially when you have to test all potential cases.
The goal of this tech preview is to scale our testing to a LOT of users.
Right now, this version should be installed on pools with 3 or 4 hosts. We plan to release another test release in one month to remove this limitation. Also, in order to ensure data integrity, it is more than recommended to use at least 3 hosts.
How to install XOSTOR on your pool?
1. Download installation script
First, you must ensure you have at least one free disk or more on each host of your pool.
Then you can download the installation script using this command:
wget https://gist.githubusercontent.com/Wescoeur/7bb568c0e09e796710b0ea966882fcac/raw/052b3dfff9c06b1765e51d8de72c90f2f90f475b/gistfile1.txt -O install && chmod +x install
2. Install
Then, on each host you must execute the script with the disks to use, for example with one partition:
./install --disks /dev/sdb
If you have many disks you can use them, BUT for optimal use, the sum of all disks should be the same on each host:
./install --disks /dev/nvme0n1 /dev/nvme0n2 /dev/nvme0n3
By default, thick provisioning is used, you can use thin instead:
./install --disks /dev/sdb --thin
Note: You can use the --force flag if you already have a VG group or PV on your hosts to override:
./install --disks /dev/sdb --thin --force
3. Verify config
With thin option
lsblk must return on each host an output similar to:
> lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
...
sdb 8:16 0 1.8T 0 disk
└─36848f690df82210028c2364008358dd7 253:0 0 1.8T 0 mpath
├─linstor_group-thin_device_tmeta 253:1 0 120M 0 lvm
│ └─linstor_group-thin_device-tpool 253:3 0 1.8T 0 lvm
└─linstor_group-thin_device_tdata 253:2 0 1.8T 0 lvm
└─linstor_group-thin_device-tpool 253:3 0 1.8T 0 lvm
...
With thick option
No LVM volume is created, only a new group must be present now using vgs command.
> vgs
VG #PV #LV #SN Attr VSize VFree
...
linstor_group 1 0 0 wz--n- 931.51g 931.51g
And you must have linstor versions of sm and xha:
> rpm -qa | grep -E "^(sm|xha)-.*linstor.*"
sm-2.30.4-1.1.0.linstor.8.xcpng8.2.x86_64
xha-10.1.0-2.2.0.linstor.1.xcpng8.2.x86_64
4. Finally you can create the SR:
If you use thick provisioning:
xe sr-create type=linstor name-label=<SR_NAME> host-uuid=<MASTER_UUID> device-config:group-name=linstor_group device-config:redundancy=<REDUNDANCY> shared=true device-config:provisioning=thick
Otherwise with thin provisioning:
xe sr-create type=linstor name-label=<SR_NAME> host-uuid=<MASTER_UUID> device-config:group-name=linstor_group/thin_device device-config:redundancy=<REDUNDANCY> shared=true device-config:provisioning=thin
So for example if you have 4 hosts, a thin config and you want a replication of 3 for each disk:
xe sr-create type=linstor name-label=XOSTOR host-uuid=bc3cd3af-3f09-48cf-ae55-515ba21930f5 device-config:group-name=linstor_group/thin_device device-config:redundancy=3 shared=true device-config:provisioning=thin
5. Verification
After that you must have a XOSTOR SR visible in XOA with all PBDs attached.
6. Update
If you want to update your LINSTOR and other packages, you can execute on each host the install script like this:
./install --update-only
F.A.Q.
How the SR capacity is calculated? 
If you can't create a VDI greater than the displayed size in the XO SR view, don't worry:
- There are two important things to remember: the maximum size of a VDI that can be created is not necessarily equal to the capacity of the SR. The SR capacity in the XOSTOR context is the maximum size that can be used to store all VDI data.
- Exception: if the replication count is equal to the number of hosts, the SR capacity is equal to the max VDI size, i.e. the capacity of the smallest disk in the pool.
We use this formula to compute the SR capacity:
sr_capacity = smallest_host_disk_capacity * host_count / replication_count
For example if you have a pool of 3 hosts with a replication count of 2 and a disk of 200 GiB on each host, the capacity of the SR is equal to 300 GiB using the formula. Notes:
- You can't create a VDI greater than 200 GiB because the replication is not block based but volume based.
- If you create a volume of 200 GiB (400 of the 600 GiB are physically used) and the remaining disk can't be used because it becomes impossible to replicate on two different disks.
- If you create 3 volumes of 100 GiB: the SR becomes fully filled. In this case you have 300 GiB of unique data and a replication of 300 GiB.
How to destroy properly the SR after a SR.forget call?
If you used a command like SR.forget, the SR is not actually removed properly. To do that you can execute these commands:
# Create new UUID for the SR to reintroduce it.
uuidgen
# Reintroduce the SR.
xe sr-introduce uuid=<UUID_of_uuidgen> type=linstor shared=true name-label="XOSTOR" content-type=user
# Get host list to recreate PBD
xe host-list
...
# For each host, you must execute a `xe pbd-create` call.
# Don't forget to use the correct SR/host UUIDs, and device-config parameters.
xe pbd-create host-uuid=<host_uuid> sr-uuid=uuid_of_uuidgen> device-config:provisioning=thick device-config:redundancy=<redundancy> device-config:group-name=<group_name>
# After this point you can now destroy the SR properly using xe or XOA.
Node: auto-eviction and how to restore?
If a node is no longer active for 60 minutes by default, it's automatically evicted. This behavior can be changed.
There is an advantage using auto evict, if there are enough nodes in your cluster, LINSTOR will create new replicas of your disks.
See: https://linbit.com/blog/linstors-auto-evict/
Now if you want to re-add your node, it's not automatic. You can used a linstor command to remove it: linstor node lost. Then you can recreate it. Also if there is no disk issue, and it was a network problem, whatever, just run one command linstor node restore.
How to use a specific network storage?
You can run few specific LINSTOR commands to configure new NICs to use. By default the XAPI management interface is used.
For more info: https://linbit.com/drbd-user-guide/linstor-guide-1_0-en/#s-managing_network_interface_cards
In case of failure with the preferred NIC, the default interface is used.
How to replace drives?
Take a look at the official documentation: https://kb.linbit.com/how-do-i-replace-a-failed-d
XAPI plugin: linstor-manager
It's possible to perform low-level tasks using the linstor-manager plugin.
It can be executed using the following command:
xe host-call-plugin host-uuid=<HOST_UUID> plugin=linstor-manager fn=<FUNCTION> args:<ARG_NAME_1>=<VALUE_1> args:<ARG_NAME_2>=<VALUE_2> ...
Many functions are not documented here and are reserved for internal use by the smapi driver (LinstorSR).
For each command, HOST_UUID is a host of your pool, master or not.
Add a new host to an existing LINSTOR SR
xe host-call-plugin host-uuid=<HOST_UUID> plugin=linstor-manager fn=addHost args:groupName=<THIN_OR_THICK_POOL_NAME>
This command creates a new PBD on the SR and new node in the LINSTOR database. Also it starts what's is necessary for the driver.
After running this command, it's up to you to set up a new storage pool in the LINSTOR database with the same name used by the other nodes.
So again use pvcreate/vgcreate and then a basic "linstor storage-pool create"
Remove a new host from an existing LINSTOR SR
xe host-call-plugin host-uuid=<HOST_UUID> plugin=linstor-manager fn=removeHost args:groupName=<THIN_OR_THICK_POOL_NAME>
Check if the linstor controller is currently running on a specific host
xe host-call-plugin host-uuid=<HOST_UUID> plugin=linstor-manager fn=hasControllerRunning
Example:
xe host-call-plugin host-uuid=ddcd3461-7052-4f5e-932c-e1ed75c192d6 plugin=linstor-manager fn=hasControllerRunning
False
Check if a DRBD volume is currently used by a process on a specific host
xe host-call-plugin host-uuid=<HOST_UUID> plugin=linstor-manager fn=getDrbdOpeners args:resourceName=<RES_NAME> args:volume=0
Example:
xe host-call-plugin host-uuid=ddcd3461-7052-4f5e-932c-e1ed75c192d6 plugin=linstor-manager fn=getDrbdOpeners args:resourceName=xcp-volume-a10809db-bb40-43bd-9dee-22d70d781c45 args:volume=0
{}
List DRBD volumes
xe host-call-plugin host-uuid=<HOST_UUID> plugin=linstor-manager fn=listDrbdVolumes args:groupName=<THIN_OR_THICK_POOL_NAME>
Example:
xe host-call-plugin host-uuid=ddcd3461-7052-4f5e-932c-e1ed75c192d6 plugin=linstor-manager fn=listDrbdVolumes args:groupName=linstor_group/thin_device
{"linstor_group": [1000, 1005, 1001, 1007, 1006]}
Force destruction of DRBD volumes
Warning: In principle, the volumes created by the smapi driver (LinstorSR) must be destroyed using the XAPI or XOA. Only use these functions if you know what you are doing. Otherwise, forget them.
# To destroy one volume:
xe host-call-plugin host-uuid=<HOST_UUID> plugin=linstor-manager fn=destroyDrbdVolume args:minor=<MINOR>
# To destroy all volumes:
xe host-call-plugin host-uuid=<HOST_UUID> plugin=linstor-manager fn=destroyDrbdVolumes args:groupName=<THIN_OR_THICK_POOL_NAME>


 (thanks Broadcom for the extra work those last months
(thanks Broadcom for the extra work those last months  )
)
 ️ UX/UI suggestions
️ UX/UI suggestions Feature improvements
Feature improvements Bug reports, please use this thread!
Bug reports, please use this thread!

 It's not production-ready yet, but that’s where you come in!
It's not production-ready yet, but that’s where you come in!