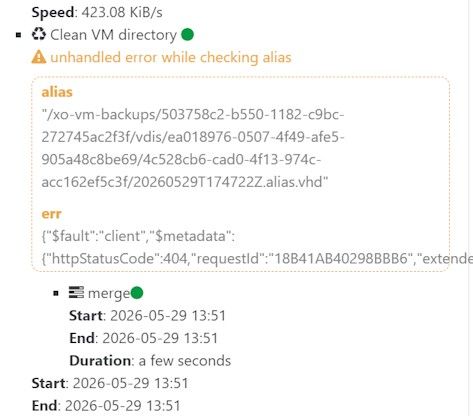
We see occasional VM backup failures that match the above pattern (ENOENT on a "path" in a S3 bucket remote destination during a VM delta backup). We are running a backup of a large VM (200GB disk) to S3 bucket in Ceph Object Gateway. Our current XO is this commit https://github.com/vatesfr/xen-orchestra/commit/da51b1649c65d7d78a4eb25cc46c488ce2552800 from 2024-03-04.
The failure is intermittent.
Example failure log:
{
"data": {
"mode": "delta",
"reportWhen": "always"
},
"id": "1712008868496",
"jobId": "49c2634a-f281-46b7-9192-aea8c786f3d4",
"jobName": "ZABBIX VM to ceph02 Delta Backup",
"message": "backup",
"scheduleId": "6b1280f0-21e7-475c-9af3-330726108568",
"start": 1712008868496,
"status": "failure",
"infos": [
{
"data": {
"vms": [
"c020890b-c1a7-79cf-0b55-aa340ba9226b"
]
},
"message": "vms"
}
],
"tasks": [
{
"data": {
"type": "VM",
"id": "c020890b-c1a7-79cf-0b55-aa340ba9226b",
"name_label": "zabbix"
},
"id": "1712008870266",
"message": "backup VM",
"start": 1712008870266,
"status": "failure",
"tasks": [
{
"id": "1712008870283",
"message": "clean-vm",
"start": 1712008870283,
"status": "success",
"end": 1712008872364,
"result": {
"merge": false
}
},
{
"id": "1712008872791",
"message": "snapshot",
"start": 1712008872791,
"status": "success",
"end": 1712008873901,
"result": "902d65f0-8c9b-2460-dad7-d041ceefebdc"
},
{
"data": {
"id": "d8d6a743-8c15-4b9a-baf4-df5d7d379b6e",
"isFull": false,
"type": "remote"
},
"id": "1712008873919",
"message": "export",
"start": 1712008873919,
"status": "failure",
"tasks": [
{
"id": "1712008875215",
"message": "transfer",
"start": 1712008875215,
"status": "success",
"end": 1712009333076,
"result": {
"size": 35343973376
}
},
{
"id": "1712009335152",
"message": "clean-vm",
"start": 1712009335152,
"status": "failure",
"tasks": [
{
"id": "1712009336153",
"message": "merge",
"start": 1712009336153,
"status": "failure",
"end": 1712009585029,
"result": {
"cause": {
"name": "NoSuchKey",
"$fault": "client",
"$metadata": {
"httpStatusCode": 404,
"requestId": "tx00000c27bed21222dc684-00660b3170-302aa3c-s3",
"attempts": 1,
"totalRetryDelay": 0
},
"Code": "NoSuchKey",
"BucketName": "xcp-ng-mama-pool-vm-backup",
"RequestId": "tx00000c27bed21222dc684-00660b3170-302aa3c-s3",
"HostId": "302aa3c-s3-s3",
"message": "UnknownError"
},
"code": "ENOENT",
"path": "/xo-vm-backups/c020890b-c1a7-79cf-0b55-aa340ba9226b/vdis/49c2634a-f281-46b7-9192-aea8c786f3d4/378753c5-9072-47b7-b879-0488a86e85ba/data/b70bc690-28c7-440a-8147-bf6d61c179de.vhd/blocks/10/52",
"message": "ENOENT: no such file or directory '/xo-vm-backups/c020890b-c1a7-79cf-0b55-aa340ba9226b/vdis/49c2634a-f281-46b7-9192-aea8c786f3d4/378753c5-9072-47b7-b879-0488a86e85ba/data/b70bc690-28c7-440a-8147-bf6d61c179de.vhd/blocks/10/52'",
"name": "Error",
"stack": "Error: ENOENT: no such file or directory '/xo-vm-backups/c020890b-c1a7-79cf-0b55-aa340ba9226b/vdis/49c2634a-f281-46b7-9192-aea8c786f3d4/378753c5-9072-47b7-b879-0488a86e85ba/data/b70bc690-28c7-440a-8147-bf6d61c179de.vhd/blocks/10/52'\n at S3Handler._copy (/opt/xo/xo-builds/xen-orchestra-202403041050/@xen-orchestra/fs/dist/s3.js:157:23)\n at process.processTicksAndRejections (node:internal/process/task_queues:95:5)"
}
}
],
"end": 1712009585029,
"result": {
"cause": {
"name": "NoSuchKey",
"$fault": "client",
"$metadata": {
"httpStatusCode": 404,
"requestId": "tx00000c27bed21222dc684-00660b3170-302aa3c-s3",
"attempts": 1,
"totalRetryDelay": 0
},
"Code": "NoSuchKey",
"BucketName": "xcp-ng-mama-pool-vm-backup",
"RequestId": "tx00000c27bed21222dc684-00660b3170-302aa3c-s3",
"HostId": "302aa3c-s3-s3",
"message": "UnknownError"
},
"code": "ENOENT",
"path": "/xo-vm-backups/c020890b-c1a7-79cf-0b55-aa340ba9226b/vdis/49c2634a-f281-46b7-9192-aea8c786f3d4/378753c5-9072-47b7-b879-0488a86e85ba/data/b70bc690-28c7-440a-8147-bf6d61c179de.vhd/blocks/10/52",
"message": "ENOENT: no such file or directory '/xo-vm-backups/c020890b-c1a7-79cf-0b55-aa340ba9226b/vdis/49c2634a-f281-46b7-9192-aea8c786f3d4/378753c5-9072-47b7-b879-0488a86e85ba/data/b70bc690-28c7-440a-8147-bf6d61c179de.vhd/blocks/10/52'",
"name": "Error",
"stack": "Error: ENOENT: no such file or directory '/xo-vm-backups/c020890b-c1a7-79cf-0b55-aa340ba9226b/vdis/49c2634a-f281-46b7-9192-aea8c786f3d4/378753c5-9072-47b7-b879-0488a86e85ba/data/b70bc690-28c7-440a-8147-bf6d61c179de.vhd/blocks/10/52'\n at S3Handler._copy (/opt/xo/xo-builds/xen-orchestra-202403041050/@xen-orchestra/fs/dist/s3.js:157:23)\n at process.processTicksAndRejections (node:internal/process/task_queues:95:5)"
}
}
],
"end": 1712009585031
}
],
"end": 1712009585032
}
],
"end": 1712009585032
}
I know I should be on the current XO to report a problem. Not asking for a fix now, just trying to document that this defect still exists.