@olivierlambert
Happy to hear that they are providing results to be looked at.
If there is anything else I can provide, please don't hesitate to ask. And I'll do my very best to be helpfull
P
Online
Posts
-
RE: " can't compute delta" & "can't connect through NBD, fall back to stream export" after 2026-07-28
-
RE: " can't compute delta" & "can't connect through NBD, fall back to stream export" after 2026-07-28
5 nbd connections went fine.
8 is not. -
RE: " can't compute delta" & "can't connect through NBD, fall back to stream export" after 2026-07-28
Thanks for looking into it further as well.. If there is a hard cap on the amount of NBD connections, then that is very interesting. Because the closest I've ever been able to find regarding this setting, was the general answer of "Try and see what works for you". So if ther is indeed a hard cap, then I would propose that this is limited inside the GUI itself. e.g. if the cap is 8, then don't let the integer exceed 8.
I'm doing increasing increments of the number of connections now. So far I've done 1,2,10. And 10 does seem to be breaking again, but only on some.
Thanks as well for the link. I'm collecting the logs through
xen-bugtool --yestoallnow. I do wish that something like this is implemented in GUI someday. And I even made a FR feedback on it. Since I really do want to provide good information for the devs. But collecting manually isn't the most convinient way unfortunately.Logs should be up shortly
-
RE: " can't compute delta" & "can't connect through NBD, fall back to stream export" after 2026-07-28
I'm doing more backup runs. And not all of the VMs trigger the warning and fall back. But it seems quite random so far.
I did one adjustment thoug.
My number of NBD connections are set quite high, 20. And after reading this post I decided to try if lowering to 1 would have an effect. And it seems that it does. The latest backup-run hasn't showed any warnings this time... Maybe it's a false lead. But it is a behaviour I noticed this time -
RE: " can't compute delta" & "can't connect through NBD, fall back to stream export" after 2026-07-28
Unfortunately I'm not able to connect logs and such until tomorrow. But I can share further info on the configs.
The backup type is Delta.
NBD is activated and reachable
The SR on the source drive is local
Target SR is truenas nfs. Transfers are as expected.Starting with the commits on 27th. These infos and fallback to full started happening. They have not been seen before. Resulting in transfers becoming 300% larger than expected.
All vdi are vhd
I compile from source almost daily. Hence me being very certain this is due to recent commits.Info warning and fallback is happening even after second attempt after latest updates as well. So issue persists between reboots as well.
Is there a vates upload service I can upload to?
Or if we reset my XO trial, I can open a support tunnel for you -
" can't compute delta" & "can't connect through NBD, fall back to stream export" after 2026-07-28
Since updating to XO from source on 2026-07-28 my backups have started showing issues:
Issue still persists on 2026-07-29 on latest commit (26c36) after the latest XCP-ng updates as well.can't compute delta OpaqueRef:4f676f19-a405-9bf7-ebb8-508240593020 from OpaqueRef:044a8fe1-7547-175f-612a-82e8df28524a, fall back to a full can't connect through NBD, fall back to stream export Backup fell back to a full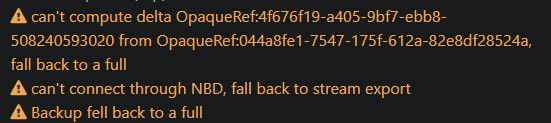
This happens to almost all of my VMs. But not on my Windows Server 2025 VM. Unsure if that is relevant though.
2026-07-27 didn't have any such notices.
-
RE: Start: no host available?
Other ideas I get are:
PCI passthrough on any of these?
Are they cloned from each other, or setup from scratch?
Afinity host / load balancing?What happens if you migrate to the other pool?
-
RE: Start: no host available?
Last time I saw that error. The resources on the host weren't enough to start the additional VM.
-
RE: XCP-ng 8.3 updates announcements and testing
@probain Hello,
It's likely linked to the
List index out of rangebug.
That bug was linked to the SR scan failing to introduceCBT_metatadataVDI in the XAPI database, could you try to launch axe sr-scan uuid=<SR UUID>and try again to disable CBT?
If it does not work, could you share the/var/log/SMlogof around the time you are trying to disable CBT?I've sent you a DM for sharing the logs.. Unfortunately I "solved" the issue by deleting all snapshots related to each VM. Including CBT ones. That did make it so I could toggle CBT on the VDIs again.
But I've collected the logs for you.
This also seems like a good time to raise my suggestion to have somewhere at vates where we could upload details in a similar way to how TrueNAS does it. Suggested here: https://feedback.vates.tech/posts/69/suggesting-to-add-a-debug-file-option
-
RE: XCP-ng 8.3 updates announcements and testing
Now receiving
UUID_INVALIDwhen trying to disable CBT on a VDI.
Perhaps a result of fixing the "List index out of range"-bug?XO Source: 5811d
Node 24vdi.set { "id": "57e0db3e-3131-40df-a620-c1118047b9d4", "cbt": false } { "code": "UUID_INVALID", "params": [ "VDI", "7b179964-dec6-4e24-a13b-8c5c56efcd95" ], "call": { "duration": 2, "method": "VDI.get_by_uuid", "params": [ "* session id *", "7b179964-dec6-4e24-a13b-8c5c56efcd95" ] }, "message": "UUID_INVALID(VDI, 7b179964-dec6-4e24-a13b-8c5c56efcd95)", "name": "XapiError", "stack": "XapiError: UUID_INVALID(VDI, 7b179964-dec6-4e24-a13b-8c5c56efcd95) at XapiError.wrap (file:///opt/xen-orchestra/packages/xen-api/_XapiError.mjs:16:12) at file:///opt/xen-orchestra/packages/xen-api/transports/json-rpc.mjs:38:21 at runNextTicks (node:internal/process/task_queues:65:5) at processImmediate (node:internal/timers:472:9)" } -
RE: (Windows) guest IPv6 address doesn't collapse zeroes -> Long IPv6 addresses
I will check back tomorrow when I'm back at that lab-pool. Sorry for taking your time thus far. I will provide more and better info tomorrow
-
RE: (Windows) guest IPv6 address doesn't collapse zeroes -> Long IPv6 addresses
So is it a display issue from XO or a problem for the tools? (not sure to get it).
What's the output of
xeCLI?This is me (jr-m4) from another (private) account.
Update: Details below are incorrect information.
xe Output for another windows 2025 guest, where I'm seeing the same behaviour[16:25 xcp ~]# xe vm-list uuid=3d3b8ba4-09c1-039d-8d58-ec797e7a05c3 params=networks networks (MRO) : 0/ip: 192.168.80.234; 0/ipv4/0: 192.168.80.234; 0/ipv6/0: fe80::4496:9d87:690d:ccc7 -
Revert to snapshot, resets creation date. Intended behaviour?
I just noticed that one VM I did a revert from snapshot on. Now that VM has that same date as its creation date. This is not really what I was expecting... Although I can somewhat se the logic/reason. It being that one could argue that it was "created" by that reverting to snapshot.. It is not indicative of when the VM itself acctually was created.
Is this intended behaviour and working as expected?
-
RE: 🛰️ XO 6: dedicated thread for all your feedback!
probain said:
Unfortunately, commit https://github.com/vatesfr/xen-orchestra/pull/9727 doesn't fix this issue of the VM-console reloading constantly. With loss of focus as a result. At least not on XO6..
-
RE: XCP-ng Windows PV tools announcements
Seems that the 9.1.146 version still reports 9.1.145-77 to XO. It is listed as the correct version in "Installed programs" within the guest (Windows server 2025).
-
RE: OIDC group to XO(CE) Admin, is it possible?
I too would love this.
They'll probably ask you to submit via the feedback website. But let me know when you've done that, and I'll vote on it as well. -
RE: Rust-based guest-tools... How are things going?
@olivierlambert said in Rust-based guest-tools... How are things going?:
The thing is that it works very well and doesn't need fixes…
 I know, not usual right? It was so stable that we left it like that waiting for people coming for bugs and nothing happened… We'll cut a 1.0 in the next weeks/months.
I know, not usual right? It was so stable that we left it like that waiting for people coming for bugs and nothing happened… We'll cut a 1.0 in the next weeks/months.I have indeed seen the stability of it myself. But the lack of updates made me worry anyway. But I'm really looking forward to the promotion to 1.0 as well.
Thanks!
-
Rust-based guest-tools... How are things going?
I'm just curious
Looking at the commit history for the Rust-based guest-tools, from the Xen-project. https://gitlab.com/xen-project/xen-guest-agent
Shows the last commit being done october 2024.. What is the status of this project? Is it dead, in hibernation, or should the xenserver-tools be used instead?
Thanks
-
RE: Setting "Protect from accidental deletion" breaks with backups and healtchecks
Also..
Thank you for taking a look at it and solving it so quickly, @florentIt is a quite nice interaction when reporting bugs that they are looked at and triaged. Not saying everything needs to be a priority 1. But I do appreciate being close to the process. And if I can help make things better by reporting bugs, in a hopefully constructive way. Then I'll continue to contribute my way.
-
RE: Setting "Protect from accidental deletion" breaks with backups and healtchecks
@florent said in Setting "Protect from accidental deletion" breaks with backups and healtchecks:
the fix is merged into master
I can confirm that the problem has now been solved. And will mark the raised github-issue as closed as well.