@joeymorin said:
I observed similar behaviour.
Two pools. Pool A composed of two hosts. Pool B is single-host. B runs a VM with XO from source. Two VMs on host A1 (on local SR), one VM on host B1 A2 (on local SR).
Host A2 has a second local SR (separate physical disc) used as the target for a CR job.
CR job would back up all four VMs to the second local SR on host A2.
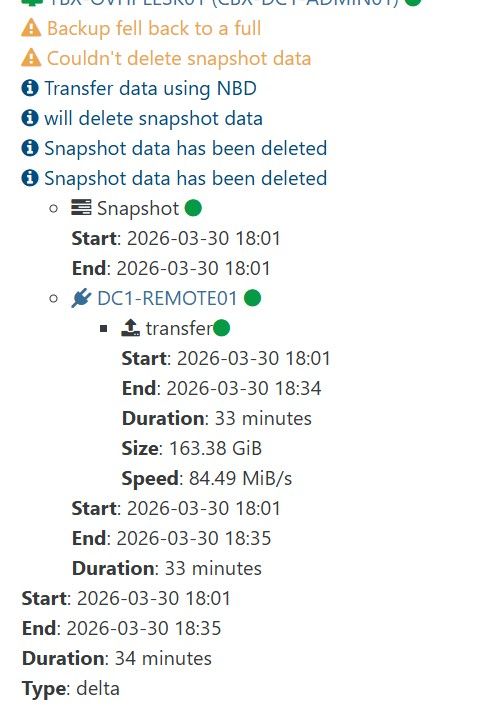
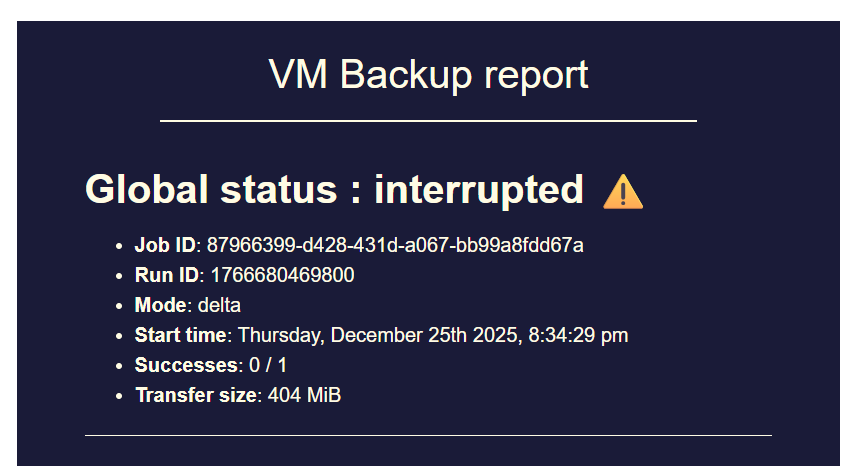
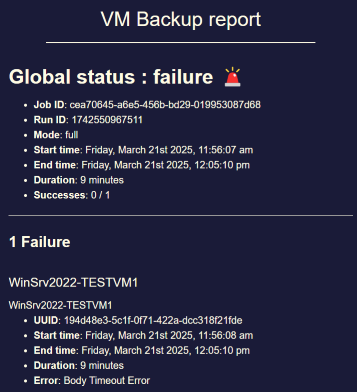
The behaviour observed was that, although the VM on B would be backed up (as expected) as a single VM with multiple snapshots (up to the 'replication retention'), the three other VMs on the same pool as the target SR would see a new full VM created for each run of the CR job. That rather quickly filled up the target SR.
I noticed the situation was corrected by a commit on or about the same date reported by @ph7.
Incidentally, whatever broke this, and subsequently corrected it, appears to have corrected another issue I reported here. I never got a satisfactory answer regarding that question. Questions were raised about the stability of my test environment, even though I could easily reproduce it with a completely fresh install.
Thanks for the work!
edit: Correction B1 A2
sometimes it's hard to find a n complete explanation without connecting to the hosts and xo, and going through a lot of logs , which is out of the scope of community support
I am glad the continuous improvement of the code base fixed the issue . We will release today a new patch, because migrating from 6.2.2 to 6.3 for a full replication ( source user that updated to the intermediate version are not affected )