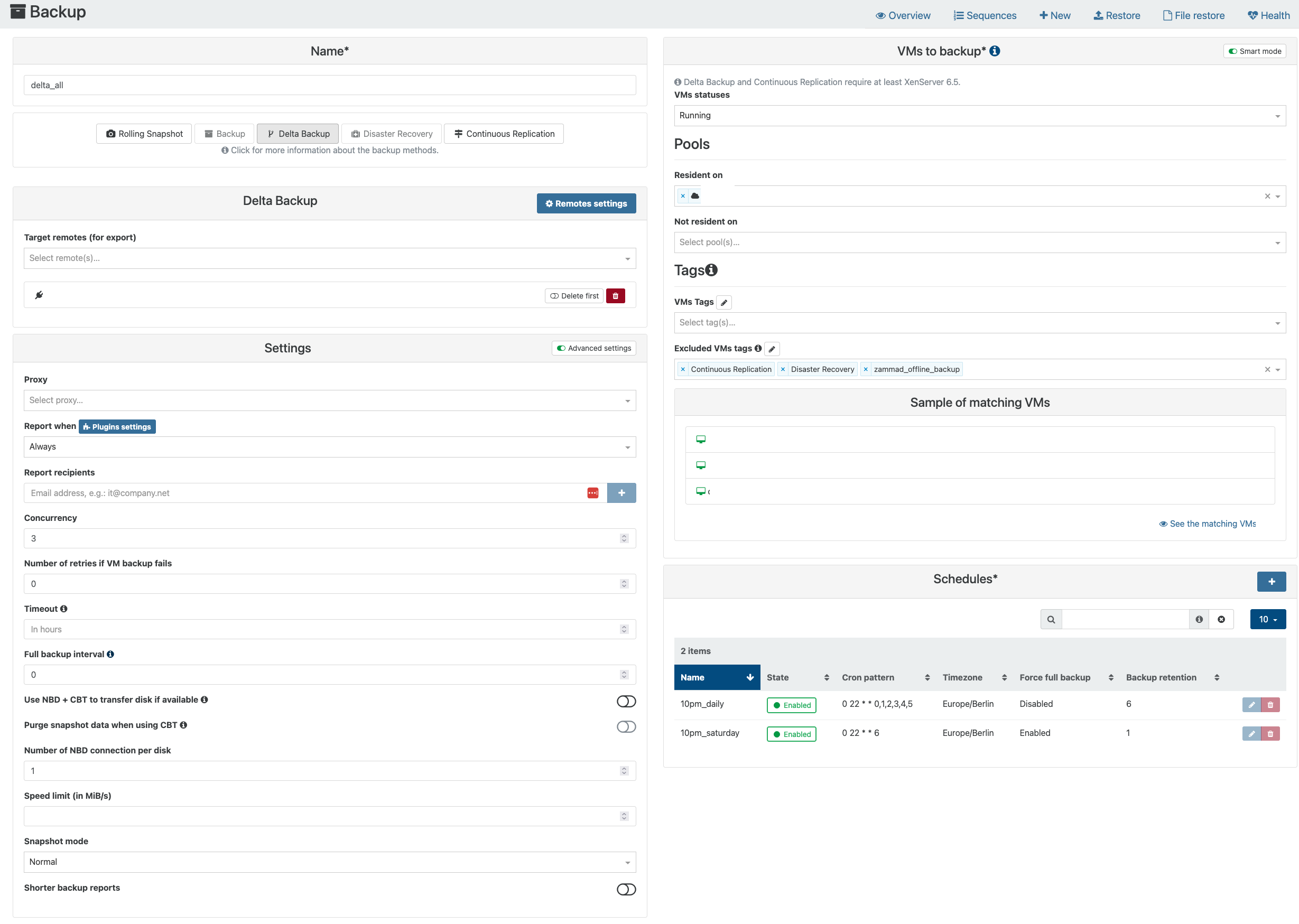
@Danp Thanks for your response.
I already tried those steps but the problem is that I am getting authorisation error.
[17:17 xcp-ng-2 ~]# iscsiadm -m session
tcp: [10] 10.204.228.100:3260,1026 iqn.1992-08.com.netapp:sn.302cea4af64811ec84d9d039ea3ae4de:vs.5 (non-flash)
tcp: [7] 10.204.228.101:3260,1027 iqn.1992-08.com.netapp:sn.302cea4af64811ec84d9d039ea3ae4de:vs.5 (non-flash)
tcp: [8] 10.204.228.103:3260,1029 iqn.1992-08.com.netapp:sn.302cea4af64811ec84d9d039ea3ae4de:vs.5 (non-flash)
tcp: [9] 10.204.228.102:3260,1028 iqn.1992-08.com.netapp:sn.302cea4af64811ec84d9d039ea3ae4de:vs.5 (non-flash)
Not sure why its giving authetication error
[17:18 xcp-ng-2 ~]# iscsiadm -m discovery -t sendtargets -p 10.204.228.100
iscsiadm: Login failed to authenticate with target
iscsiadm: discovery login to 10.204.228.100 rejected: initiator failed authorization
iscsiadm: Could not perform SendTargets discovery: iSCSI login failed due to authorization failure
[17:18 xcp-ng-2 ~]#
If iscsi daemon has logged out then how I am able to access the VMs?
If iscsi daemon has logged out then how I am able to migrate VM from one xcp-ng node to another?
For migration and accessing VM, xcp-ng should be able to communicate SR, right?
However, I tried restart iscsi service in one of the xcp-ng node on which 2 VMs were there. One on local storage of the xcp-ng and another on the SR.
When I restarted the iscsid service and logged out and logged in to the storage, login failed giving authorisation error (not sure why it gave error, strange) and then both the VMs alongwith the xcp-ng node rebooted automatically
Once xcp-ng node came up, iscsi daemon automatically logged in to the storage.
I am not sure what to do in this case. Your support is much appreciated.