I am running NVIDIA P40s on a DELL R720/R730 and a NVIDIA A2000 12GB on a DELL Optiplex 9010 in my playlab. Getting the GPUs to be accessible for VMs was quite easy: shutdown the XCP-ng host, install the GPUs, start the host again, activate the GPU in the advanced settings of the host in the PCI Devices section (“Passthrough enabled”). The host will restart at this point after displaying a warning. That's it – the GPU can now be assigned to a VM in the VMs advanced settings. I do use the GPUs for AI workloads under Debian though, so your use case might vary.
Posts
-
RE: GPU Passthrough
-
Can’t Reach iDRAC via OS-to-iDRAC Pass-Through on XCP-ng + Debian 12 VM
Hi everyone, I’m currently working with XCP-ng 8.3 (fully updated) on a Dell PowerEdge R720 in my homelab, and I’m trying to access the iDRAC interface of the same server from a Debian 12 VM using ipmitool. I want to use the OS-to-iDRAC Pass-Through feature (USB NIC) to allow the VM to communicate directly with the iDRAC, so I can run ipmitool commands like power status, fan control, etc., from within the VM without going over the network (which is segmented off).
What is working
- The iDRAC Pass-Through feature is enabled in the iDRAC web interface under: iDRAC Settings → Network → OS to iDRAC Pass-Through (USB NIC set to the IP: 169.254.0.1)
- The iDRAC network test confirms it’s working.
- The pass-through interface (PIF) appears in XCP-ng’s host network list as idrac.
- I’ve attached it to a Debian 12 VM, where it shows up as enX1.
- The VM has correctly assigned 169.254.0.2/24 via /etc/network/interfaces.
Despite the correct IP assignment, I cannot ping 169.254.0.1 from the VM:
# Output of ip a (shortened) 3: enX1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether d6:24:9e:46:de:64 brd ff:ff:ff:ff:ff:ff inet 169.254.0.2/24 brd 169.254.0.255 scope global enX1ping 169.254.0.1 # Output: # From 169.254.0.2 icmp_seq=1 Destination Host Unreachable # (repeats)And ipmitool fails with:
ipmitool -I lanplus -H 169.254.0.1 -U <user> -P <password> power status # Error: Unable to establish IPMI v2 / RMCP+ sessionTested the same as a bare metal setup on another R720 with Debian 12 and that worked as expected. I have a distinct feeling that I have asked this question before, but unfortunately I can't find the post anymore.
Any insights, tips, or similar experiences would be greatly appreciated!
-
RE: XCP-ng 8.3 updates announcements and testing
@gduperrey Works on my play-/homelab (HP ProDesk 600 G6, Dell Optiplex 9010). Can't update my Dell R720s GPU cluster at the moment, though.
-
RE: XCP-ng 8.3 updates announcements and testing
@stormi Updated the usual suspects (HP ProDesk 600 G6, Dell Optiplex 9010, Dell R720) with no problem. Host run as expected.
-
RE: XCP-ng 8.3 updates announcements and testing
@stormi Update two pools with a total of six host (HP ProDesk 600 G6 and Dell Optiplex 9010) and two Dell R720 with GPUs. Update went smooth and no issues running for two days now (with backup and restore)
-
RE: XCP-ng 8.3 updates announcements and testing
@Greg_E You need to update all members of a pool, starting with the pool coordinator (including reboot if needed), followed by each member.
-
RE: XCP-ng 8.3 updates announcements and testing
@gduperrey Updated two Dell R720 servers (dual E5-2640v2, 128GB RAM, with GPUs) and a Dell R730 server (dual E5-2690v4, 512GB RAM, with GPUs) without issues. The services (VMs) are working as expected, so we'll see how the systems perform over the next few days
-
RE: XCP-ng 8.3 updates announcements and testing
@gduperrey Installed on some R720s with GPUs and everything works as expected. Looks good

Edit: also installed the update on my playlab hosts and a Dell PowerEdge R730. Again no issues and all hosts and VMs are up again.
-
RE: Some questions about vCPUs and Topology
@jasonnix Not an expert on this topic, but my understanding is that 1 vCPU can be understood as 1 CPU core or - when available - 1 CPU thread. Since vCPU's are used for resource allocation by the hypervisor, vCPU overprovisioning can make things more complicated.
VMs or memory-sensitive applications sometimes make memory locality (NUMA) decisions based on the topology of the vCPUs (sockets/cores) presented by the hypervisor, which is why you can choose different topologies. You can read more on NUMA affinity in the XCP-ng documentation. In a homelab, you rarely have to worry about this and as a rule of thumb, you can use virtual sockets with 1 core for the amount of vCPUs you need (which is the standard for XCP-ng and VMware ESXi).
Sometimes it still makes sense to keep the number of sockets low and the number of cores high, as sockets or cores can be a licensing metric that determine license costs. However, most manufacturers already take this into account in their terms and conditions.
In a somewhat (over-) simplified form: socket/core topologies can be used in some special scenarios to optimize memory efficiency and performance or to optimize licensing costs.
-
RE: How to Migrate VMs Seamlessly in Xen Orchestra ??
@danieeljosee If your XCP-ng pool is set up correctly, live migration with Xen Orchestra works straight away. Compatibility is key in a pool (CPU manufacturer, CPU architecture, XCP-ng version, network cards/ports). There is a lot of leeway for CPU architecture, but I would recommend not mixing new and older CPU generations.
For the network settings, it depends on your network architecture. You can run all network traffic via one NIC or you can separate the network traffic from management, VM migration, VM and/or storage/backup using more NICs. In a homelab, one NIC is usually sufficient.
While shared storage is very helpful for VM live migration, you can also live migrate the VM with its disks attached on local storage. Just select the destination host and destination storage repository. For local storage, VMs and attached disks must of course be located on the same destination host.
Check out Tom's YT channel as @ph7 suggested.
-
RE: Nvidia P40s with XCP-ng 8.3 for inference and light training
@Vinylrider Cool modification, but definitely not for the faint-hearted. Is it difficult to cut through the metal? Interestingly, in your setup, the end with the 4x black wires connects to the riser card. With my setup / cable, it's the 5x black wire end that plugs into the riser card. Mh, I saw that on youtube but never gave it much thought until now.
Since my R720s can’t natively monitor GPU temperatures of this GPUs to adjust fan speeds, I’m planning to create a script that reads both CPU and GPU temperatures and dynamically controls the fan speed through iDRAC. My R720s, equipped with two Intel Xeon CPU E5-2640 v2 processors (TDP of 95W), don’t typically run too hot though, even under load.
Here’s a quick temperature chart I’ve put together for my setup, showing CPU and GPU temperatures at various fan speeds (adjusted via iDRAC) - both at idle and under load:
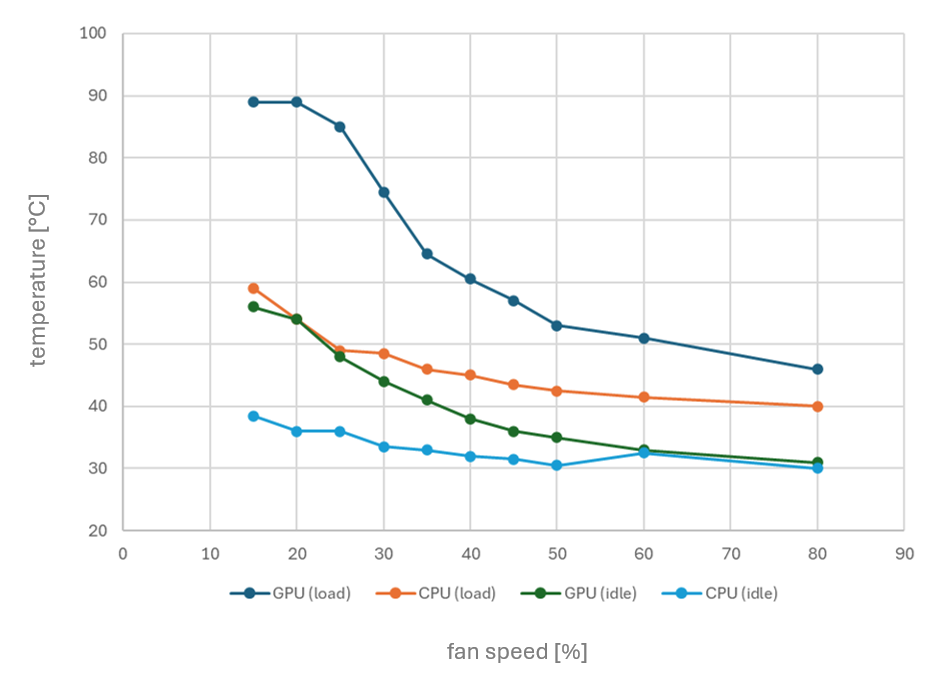
With the automatic fan control at 45%, both CPU and GPU temperatures remain comfortably below 60°C, even under load.
-
RE: NVIDIA Tesla M40 for AI work in Ubuntu VM - is it a good idea?
@CodeMercenary Did some tests with the A2000 and as expected, the 12GB VRAM is the biggest limitation. Used vanilla installations of Ollama and ComfyUI with no tweaking or optimization. Especially in stable diffusion, the A2000 is about three times faster compared to the P40, but that is to be expected. I have added some results below.
Stable Diffusion tests
A2000 1024x1024, batch 1, iterations 30, cfg 4.0, euler 1.4s/it 1024x1024, batch 4, iterations 30, cfg 4.0, euler 2.5s/it = 0.6s/it P40 1024x1024, batch 1, iterations 30, cfg 4.0, euler 2.8s/it 1024x1024, batch 4, iterations 30, cfg 4.0, euler 12.1s/it = 3s/itInference tests
A2000 qwen2.5:14b 21 token/sec qwen2.5-coder:14b 21 token/sec llama3.2:3b-Q8 50 token/sec llama3.2:3b-Q4 60 token/sec P40 qwen2.5:14b 17 token/sec qwen2.5-coder:14b 17 token/sec llama3.2:3b-Q8 40 token/sec llama3.2:3b-Q4 48 token/secDuring heavy testing, the A2000 reached 70°C and the P40 reached 60°C both with the Dell R720 set to automatic fan control.
-
RE: XCP-ng 8.3 updates announcements and testing
@gduperrey Update some Dell R720s with GPUs and a Dell R730. Update worked without any problem and VMs operate as expected. Will update this post if that changes during day-to-day operation. Great work!
-
RE: NVIDIA Tesla M40 for AI work in Ubuntu VM - is it a good idea?
@CodeMercenary I got my hands on a Nvidia RTX A2000 12GB (around 310€ used on Ebay) which might be an option, depending on what you want to do. It is a dual slot low profile GPU with 12GB VRAM, a max power consumption of 70W and active cooling. With a compute capability of 8.3 (P40: 6.1, M40: 5.2) it is fully supported by
ollama. While 12GB is only 50% of one P40 with 24GB VRAM, it runs small LLMs nicely and with a high token per second rate. It can almost run the Llama3.2 11b vision model (11b-instruct-q4_K_M) using the GPU with only 3% offloaded to CPU. I will start testing this card during the weekend and can share some results if that would help.
-
RE: NVIDIA Tesla M40 for AI work in Ubuntu VM - is it a good idea?
@CodeMercenary I didn't know there was a midboard hard drive option for the R730xd - cool. You could always install a couple Nvidia T4s, but they only come with 16GB of VRAM and are much more expensive compared to the P40s. For reference, I've added a top view of the R720 with two P40s installed.

-
RE: Passthru of Graphics card
@manilx Maybe this post on Intel iGPU passthough gives some ideas? You probably loose the video output on the Protectli when you assign the iGPU to a VM.
-
RE: NVIDIA Tesla M40 for AI work in Ubuntu VM - is it a good idea?
@CodeMercenary The M40 is a server card and (physically) compatible with the R730, so no extra cooling is required (and possible). The downside is that the R730 most likely will still go full blast on all fans regardless of the actual power consumption since the server can not read the GPUs temperature. But there are scripts to manage the fan speeds based on server or GPU temperature. And once you have ollama installed, you can ask it how to write that code
")
-
RE: NVIDIA Tesla M40 for AI work in Ubuntu VM - is it a good idea?
@CodeMercenary Probably not insane if you want to learn using ollama or other LLM frameworks for inference. But the M40 is an ageing GPU with a low compute capability (v5.2), so with time, it might not be supported any more by platforms like ollama, vLLM, llama.cpp or aprhodite (did not check if they actually support that GPU, but Ollama has support for the M40). I doubt that you get an acceptable performance for stable diffusion (image generation) or training/fine-tuning. But what could you expect for $90?
The card has a power consumption (TDP) of 250W which is compatible with the 16x PCIe slot of riser #2. You have to be extra careful with the cable as it is not a standard cable. While most would suggest power supplies of 1100W for the Dell R730 to be on the save side, I run two P40s with 750W power supplies in a Dell R720. But I also power limit the card to 140W with little effect on the performance and have light workloads and no batch processing.
-
RE: XCP-ng 8.3 betas and RCs feedback 🚀
@olivierlambert People might be a little crazy, but they also have trust in the test and RC lifecycle of XCP-ng, which has proven to be very reliable thanks to the dedication of the Vates team and also the community. But I agree, for production use it's better to wait for a GA announcement. Anyway, congratulation to this important milestone in the development of XCP-ng
 .
. -
RE: XCP-ng 8.3 betas and RCs feedback 🚀
@bleader There is a
xcp-ng-8.3.0.isoon the ISO repository. Is that the release of XCP-ng 8.3 ? Looking forward to an official announcement
? Looking forward to an official announcement  .
.