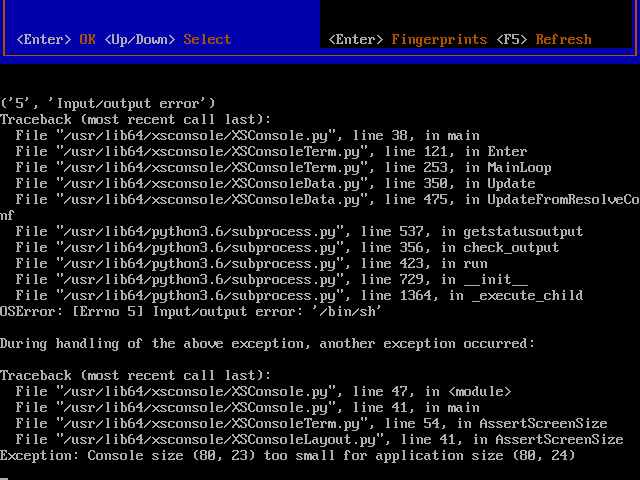
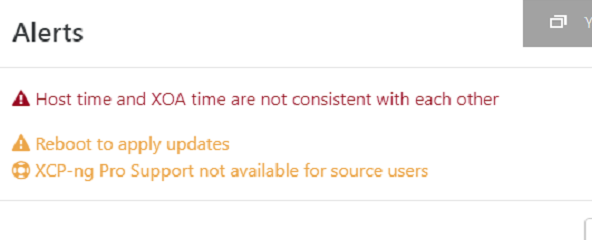
@tjkreidl We don't need performance, but we do need to test how XCP-ng pools, networking, migration, live migration, backup, import from VMware and so on work. It's just a playground where we can have relatively many XCP-ng hosts, but it's not about performance, it's about efficiency and low requirements, because it's just a playground where we learn, validate how things work, and prepare the process for the final migration from VMware to XCP-ng. We originally had two R630s ready for this, then 4, but that would have been unnecessary, given the power consumption, to have physical hypervisors, so in the end we decided to virtualize it all. Well, on ESXi it's because XCP-ng works seamlessly there in nested virtualization.