Hi @acebmxer,
I've made some tests with a small infrastructure, which helped me understand the behaviour you encounter.
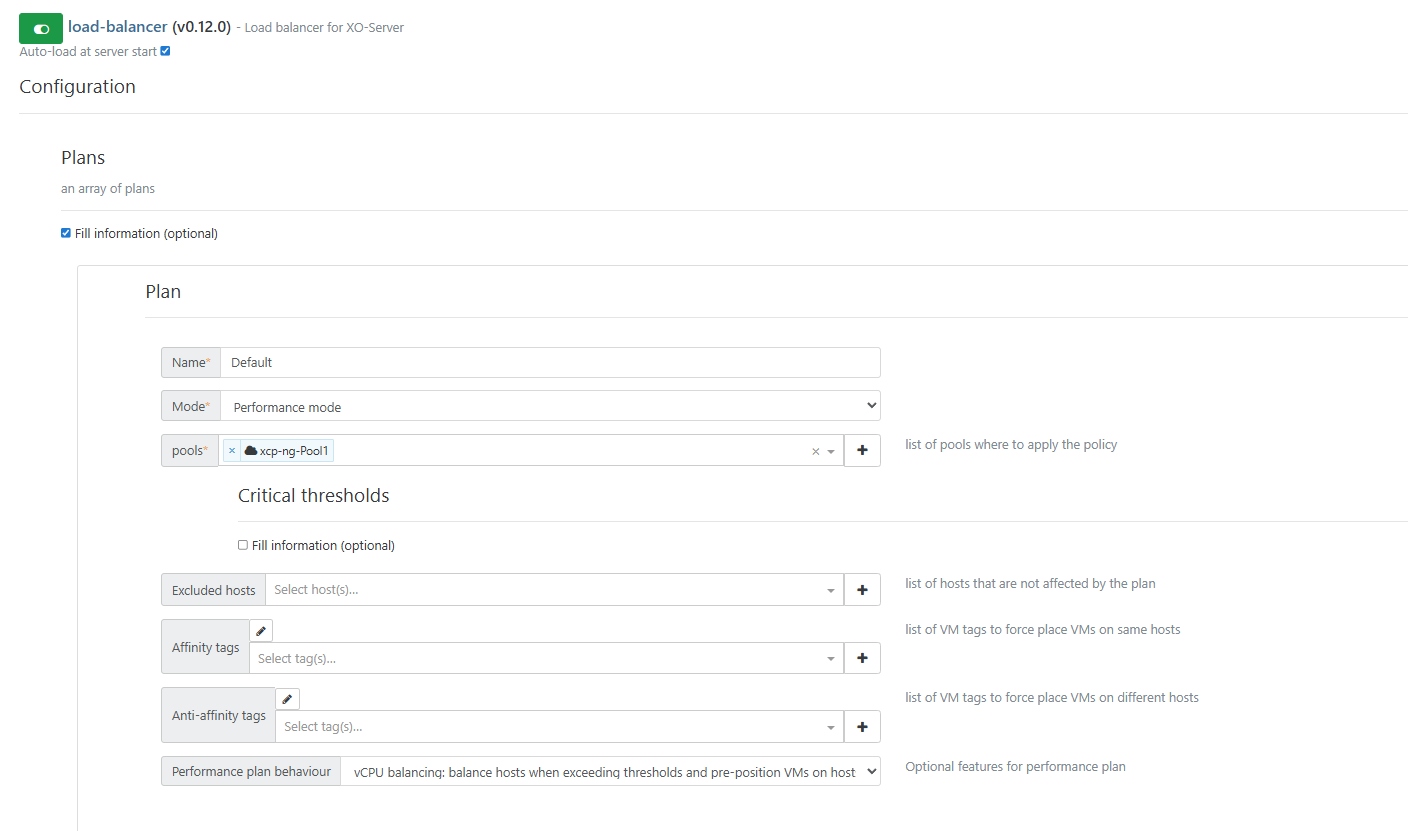
With the performance plan, the load balancer can trigger migrations in the following cases:
to better satisfy affinity or anti-affinity constraints
if a host has a memory or CPU usage exceeds a threshold (85% of the CPU critical threshold, of 1.2 times the free memory critical threshold)
with vCPU balancing behaviour, if the vCPU/CPU ratio differs too much from one host to another AND at least one host has more vCPUs than CPUs
with preventive behaviour, if CPU usage differs too much from one host to another AND at least one host has more than 25% CPU usage
After a host restart, your VMs will be unevenly distributed, but this will not trigger a migration if there are no anti-affinity constraints to satisfy, if no memory or CPU usage thresholds are exceeded, and if no host has more CPUs than vCPUs.
If you want migrations to happen after a host restart, you should probably try using the "preventive" behaviour, which can trigger migrations even if thresholds are not reached. However it's based on CPU usage, so if your VMs use a lot of memory but don't use much CPU, this might not be ideal as well.
We've received very few feedback about the "preventive" behaviour, so we'd be happy to have yours.
As we said before, lowering the critical thresholds might also be a solution, but I think it will make the load balancer less effective if you encounter heavy load a some point.